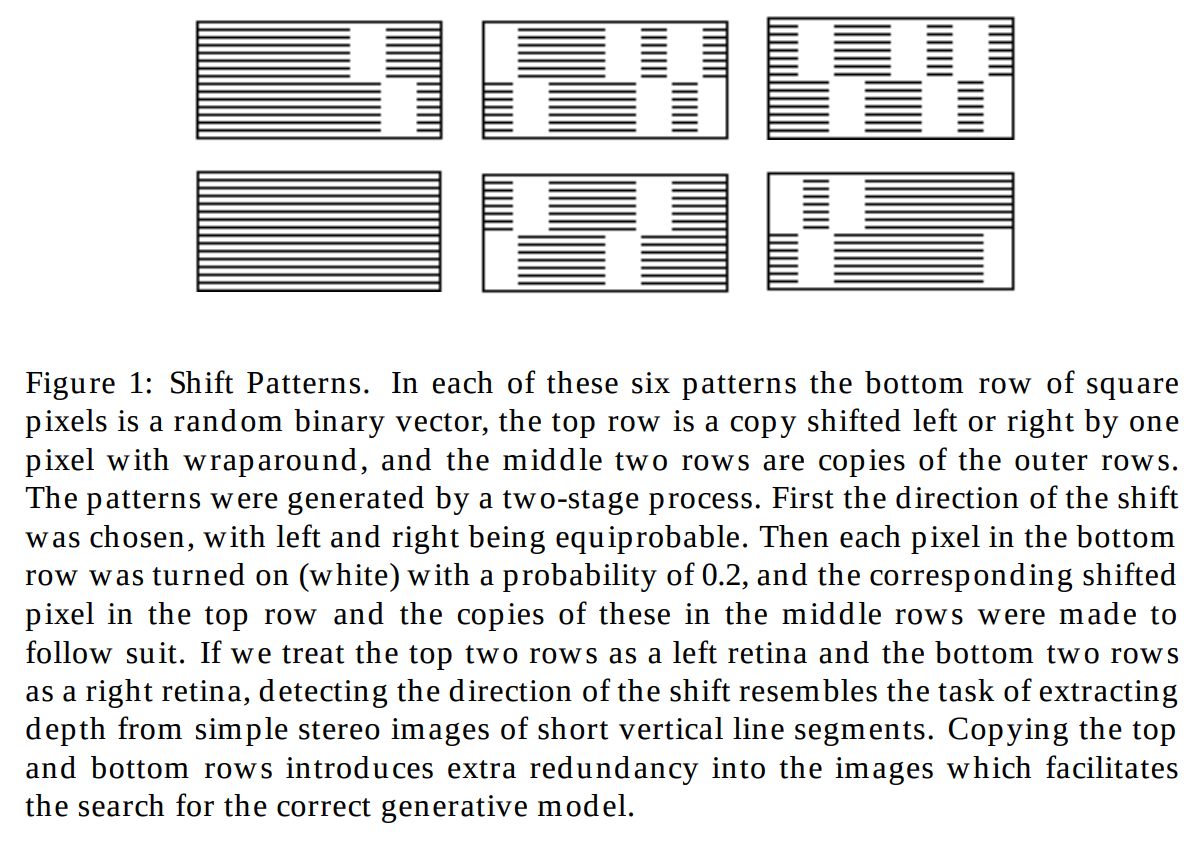
VAE: AutoEncoder에서 VQ-VAE까지
암호학의 encoder, decoder의 출발과 초기의 AutoEncoder에서 최신의 AutoEncoder가 어떻게 보완하며 발전했는지를 배우는 과정에서 자연스럽게 latent space와 vector가 무엇인지 학습한다. 또한 어떻게 주어진 상황을 수학적으로 모델링 하는지를 배우고 그 아이디어가 어떻게 현대 생성모델와 연결되는지 배운다.
구성
AutoEncoder의 초기 모델이 어떻게 VQ-VAE까지 연결이 되어 generative model이 되는 과정을 역사적으로 학습하면서, 각 이론의 한계와 의의를 정리한다.
강의를 시작하기전에 아래의 모든 모델의 결론은 결국, "고양이 사진 한 장을 새로 만들어내는 모델을 어떻게 설계할 것인가?" 라는 질문에 대해 수학적으로 고민한 흔적들이라는 것이다. 40년전 마리오와 테트리스가 최고급 그래픽이던 시절, 수학자들과 통계학자 그리고 컴퓨터 공학자들이 상상으로 이 질문에 답을 하기 위해 무엇보다 이론을 단단하게 정립해야했고, 그것이 가장 잘 정리된 분야중 하나가 AutoEncoder이다. 당연하게도, 자연스러운 흐름에서 이들은 때로는 암호학에서 때로는 통계물리학과 생물학에서 개념을 가지고 왔다. 당시에는 그들의 ML개념이 제대로 분리되지 않은 채 정립되기 시작한 학문이였기 때문이다. 1980년 부터 neural network 이전 시대의 개념인 암호학의 encoder와 decoder로부터 neural network 기반의 학습 가능한 구조와 그 분석, 가장 초기 형태의 AutoEncoder가 제안되고 해석된다 (Ballard). 이러한 역사적 흐름이 중요한 이유는 어떤 기술이 어떤 목적과 철학에서 나왔는지를 알게되면 비로소 그 기술을 어디에 제대로 적용할수 있는지를 알기 때문이라고 나는 믿는다. 요즘 보면 latent vector라는 말을 마치 만능처럼 사용하는 사람들과 그것이 어떤 특성을 가진지 모른채 적절한 장소에 끼워넣을려는 시도가 많이 보인다. 그러한 일이 나쁜것은 아니나, 우리가 모델의 발전과정을 배우면 그곳에서 자연스럽게 MLP와 latent space이 왜 생겼고 어떤 특성을 가졌는지 쉽게 배우고 이해할수 있다. AutoEncoder라는 분야는 ML이라는 역사적으로 중요한 위치를 가지는데 기초적인 모델의 수학적 해석과 이해에 대한 논문이 바로 AutoEncoder의 구조를 설명하는 과정에서 많이 나왔기 때문이다. AutoEncoder가 ML중에서도 특히 수학적으로 많이 해석된 영역인 이유는 auto Auto-associative라고 하는 입력과 출력의 차원과 데이터가 같은 구조로 부터 스스로 학습하는 이 구조가 비교적 다른 supervised model에 비해 데이터나 수학적 정의가 깔끔하고 편리했기 때문일 것이다. 그리고 VAE 그 중에서 가장 ML스럽고 수학적으로 잠재벡터에 접근한 방법이라 믿는다. β-VAE, VQ-VAE는 이러한 VAE위에서 잠재공간의 성질을 수학적으로 세분화하여 VAE가 지원하지 않는 한계점들을 풀기 위한 방법론이라고 볼수 있다. 마지막으로 이러한 VAE흐름이 더 부각되는 이유는 위의 방식들을 최근 이미지나 다양한 생성모델의 seed를 공급하기 위한 모델로써 활용하면서 그 중요성이 올라오기 때문이다. 우리는 이러한 발전의 흐름을 공부하면서 이것이 가지는 수학적의미와 구조 그리고 의의와 한계를 파악한다. 강의의 흐름아래와 같이 진행하며,
AutoEncoder는 처음에 입력층, 그보다 차원이 작은 가운데 층, 출력층으로(3-layer) 이루어진 단순한 구조였다. 이 가운데 층의 활성함수가 선형인 경우를 지금은 Linear AutoEncoder라고 부른다. 이것의 전역 최적해가 PCA와 같은 주부분공간(principal subspace)을 학습함이 1989년에 밝혀졌다 [2]. 여기서 연구가 두 갈래로 갈라진다. 한 갈래는 PCA를 확률을 도입한 생성 모델인 PPCA 이고, 다른 한 방향은 AutoEncoder를 확률과 정보이론의 틀로 재해석한 neural network 계보 (Hinton-Zemel의 연구, 그리고 Helmholtz Machine) 이다. 한편 비선형, 즉 활성 함수에 시그모이드같은 비선형 함수를 넣은 Deep AutoEncoder가 더 높은 성능을 보였다. Helmholtz Machine은 AutoEncoder구조를 잠재 벡터(또는 잠재 코드)를 도입하고 잠재 코드를 만들고 해석하는 recognition model과 generative model를 페어로 둔 역사적인 연구이다. 이 연구에서 Hinton은 AutoEncoder의 구조를 통계물리학의 개념과 결합하여 볼츠만 분포로 해석하고 에너지 관점에서 분산을 해석하여 분산을 최소화하는 방향으로 모델의 학습이 수렴될수 있음을 최초로 보였다. 이러한 잠재공간에 대한 연구는 isomap (테넨바움)으로부터 데이터의 분포와 해당 분포에서 생성된 latent space가 단순히 선형이 아닌 휘어있는 등 비선형적 구조를 가질수 있음에 대한 증거를 보였다. VAE는 Helmholtz Machine과 Deep AutoEncoder의 장점을 합치고, 잠재변수 샘플링이 미분 불가능하다는 한계를 Reparameterization trick으로 해결한 모델이다. recognition model과 generative model의 짝 구조를 그대로 사용하돼 학습을 단일 ELBO로, decoder를 비선형 neural network으로 확장한 모델이다.
정리하면 Linear AE = PCA의 증명 이후 PCA를 확률화하면 PPCA, autoencoder 틀을 정보이론으로 재해석하면 neural network 계보 (Hinton-Zemel) 로 갈라진다. 굵은 보라색은 VAE 원논문이 직접 언급한 레퍼런스 (Helmholtz Machine의 wake-sleep을 ELBO로 통합) 이다. Deep AE는 직접 인용 대상은 아니나 VAE decoder를 비선형 neural network으로 만든 시대적 배경이다. 자세한 논의는 2.4.3 참조.
이제 본격적으로 강의를 시작하며, 학습할 점들에 대해 bullet point로 정리하고 넘어간다.
- encoder-decoder 구조와 auto-association의 개념, 그리고 머신러닝이 이 고전 용어를 어떻게 변형해 받아들였는지 (1장)
- 보조자료: 알면 좋은 수학적 도구들.
- Auto-association의 정의와 대해 간략하게 수학적으로 모델링 해보기
- Linear AutoEncoder 의 정의와 구조
- Linear AutoEncoder 의 전역해가 PCA와 같음에 대한 증명: Bardi-Hornik
- likelihood의 수학적 모델링 기초
- latent vector and latent space
- VAE, β-VAE, VQ-VAE 각 모델의 차이점(2장 ~ 5장)
- latent를 점으로 두는 모델 (AE) 과 분포로 두는 모델 (VAE) 의 차이, prior와 posterior가 만드는 확률 구조 (3장)
- variational inference와 ELBO: 직접 최대화할 수 없는 $\log p(x)$를 하한으로 다루는 방법, reparameterization trick으로 학습을 가능하게 만드는 방법 (3장)
- reparameterization trick이란
- 전체 정리 및 Variation inference
암호학적 기원
머신러닝의 "encoder"와 "decoder"는 neural network 이전 시대의 용어이다. 그 기원과 함께, 머신러닝이 이 개념을 도입하면서 변형한 부분을 정리한다.
1.1 통신과 암호의 문제 의식
전쟁 중의 무전 통신을 예로 들 수 있다. 무전기로 정보를 송신하는 상황에서 적군이 무전을 감청한다고 가정하자. 평문을 그대로 송신하면 적군 역시 동일한 정보를 손에 넣는다. 따라서 송신자는 미리 약속된 규칙에 따라 메시지를 변환하여 전송하고, 수신자는 같은 규칙을 역으로 적용하여 원문을 복원해야 한다. 가장 단순한 예가 시저 암호로, 자모를 일정 칸만큼 옮기는 변환이다.
이 과정은 두 함수로 표현된다.
encoder는 원문 $x$를 변환된 표현 $y$로 보내는 함수 $f: \mathcal{X} \to \mathcal{Y}$이고, decoder는 그 역으로 $y$로부터 원문 $x$를 복원하는 함수 $g: \mathcal{Y} \to \mathcal{X}$이다. 변환 후의 표현 $y$를 인코딩(encoding)이라 부른다.
고전 암호학에서는 $g$가 $f$의 역함수 관계에 놓여져야 하고, $f$는 bijection이어야 한다. 그렇지 않으면 복원이 불가능하기 때문이다. 시저 암호의 경우, $f(x) = (x + k) \bmod 26$과 $g(y) = (y - k) \bmod 26$이 정확히 대응된다.
1.2 encoder-decoder의 일반화
현대에 이르러 encoder-decoder라는 abstraction은 암호 이외의 영역으로 광범위하게 확장되었다. 정보를 어떤 표현으로 변환하였다가 되돌리는 $(f, g)$ pair에서 각각을 encoder-decoder 라고 하며, 이는 데이터 $f(x)=y$ 와 $x$를 이진화 했을때의 길이에$\ell$ (bit 단위)따라 세 가지로 분류할 수 있다.
| 분류 | 부호 길이 변화 | 예시 |
|---|---|---|
| Length-preserving | $\ell(y) = \ell(x)$ | Caesar cipher, ROT13, 단순 substitution cipher. Symbol만 바뀌고 길이가 같다. |
| Redundant | $\ell(y) > \ell(x)$ | Hamming code, Reed-Solomon, Base64. Noisy channel에서의 복원 또는 6-bit 단위 안전한 전송을 위해 부호 길이를 늘린다. |
| Compressive | $\ell(y) < \ell(x)$ | JPEG, MP3, ZIP, AutoEncoder. Lossless 또는 lossy compression. |
AutoEncoder에서 다루는 encoder-decoder 모델은 대부분 세 번째 부류, compressive에 속한다. 이러한 구조가 ML에서 가지는 이점은 단순히 부호 길이를 줄이는 것이 아니라, 데이터의 의미 구조를 보존하면서 최소의 정보로 데이터를 표현하는 구조를 학습하는것이 목적이다.
1.3 머신러닝의 두 가지 차이
머신러닝의 encoder-decoder는 고전 암호학의 정의에서 두 부분이 변형된 형태로 볼수 있다.
차이 1: $g$가 정확한 역함수가 아니다. 고전 암호학에서 $g = f^{-1}$는 필수 요건이지만, 머신러닝은 의도적으로 $g$를 근사적 역함수로 정의한다. 정보를 완벽히 보존하지 않고 일부를 잃는 것이 허용된다.
차이 2: 복원이 완전하지 않다. 이 점은 출력에 모자(hat) 기호를 붙여 $\hat{x}$로 표기하는 관습으로 드러난다. 통계학에서 추정량을 표시할 때 쓰는 기호와 같으며, "원본의 추정치"라는 의미를 명시한다.
이렇게 약하게 정의하는 이유는 머신러닝의 목적이 메시지 보존이 아니라 의미 추출에 있기 때문이다. 만약 $g$를 완벽한 역함수로 강제한다면 중간 표현 $z$는 단순히 $x$를 다른 비트열로 다시 적은 것에 불과해진다. 즉, 정보 손실은 없으되 의미가 추출된 것도 아닌 상태가 된다.
머신러닝이 원하는 $z$는 $x$로부터 의미적으로 중요하지 않은 정보(개별 픽셀의 미세한 noise, 배경의 사소한 변동 등)를 제거하고 핵심만 남긴 표현이다. 이러한 $z$를 데이터의 표현(representation) 또는 latent vector라고 부른다. 정보를 의도적으로 버리는 것이 목적인 이상, $g$가 정확한 역함수일 수는 없다.
이 abstraction 형태의 encoder-decoder 구조는 머신러닝의 광범위한 영역에서 등장한다. seq2seq 번역 모델(encoder가 소스 문장, decoder가 타겟 문장), U-Net 분할 모델, Transformer의 encoder-decoder 구성 등이 모두 같은 abstraction 위에 놓인다. 본 강의의 대상은 그 중에서도 가장 단순한 형태, 곧 입력과 출력이 동일한 경우이다.
AutoEncoder: 정의, 수학적 토대, 그리고 한계
AutoEncoder의 구조와 손실 함수를 정의하고, 그 학습이 데이터로부터 어떤 표현을 끌어내는지 분석한다. 분석 끝에서 AutoEncoder가 generative model로 작동하지 못하는 이유와 그 해결의 방향이 자연스럽게 따라 나온다.
1.4 AutoEncoder 에서의 Encoder Decoder
이러한 정의는 AutoEncoder에서 다음과 같이 정의 된다.
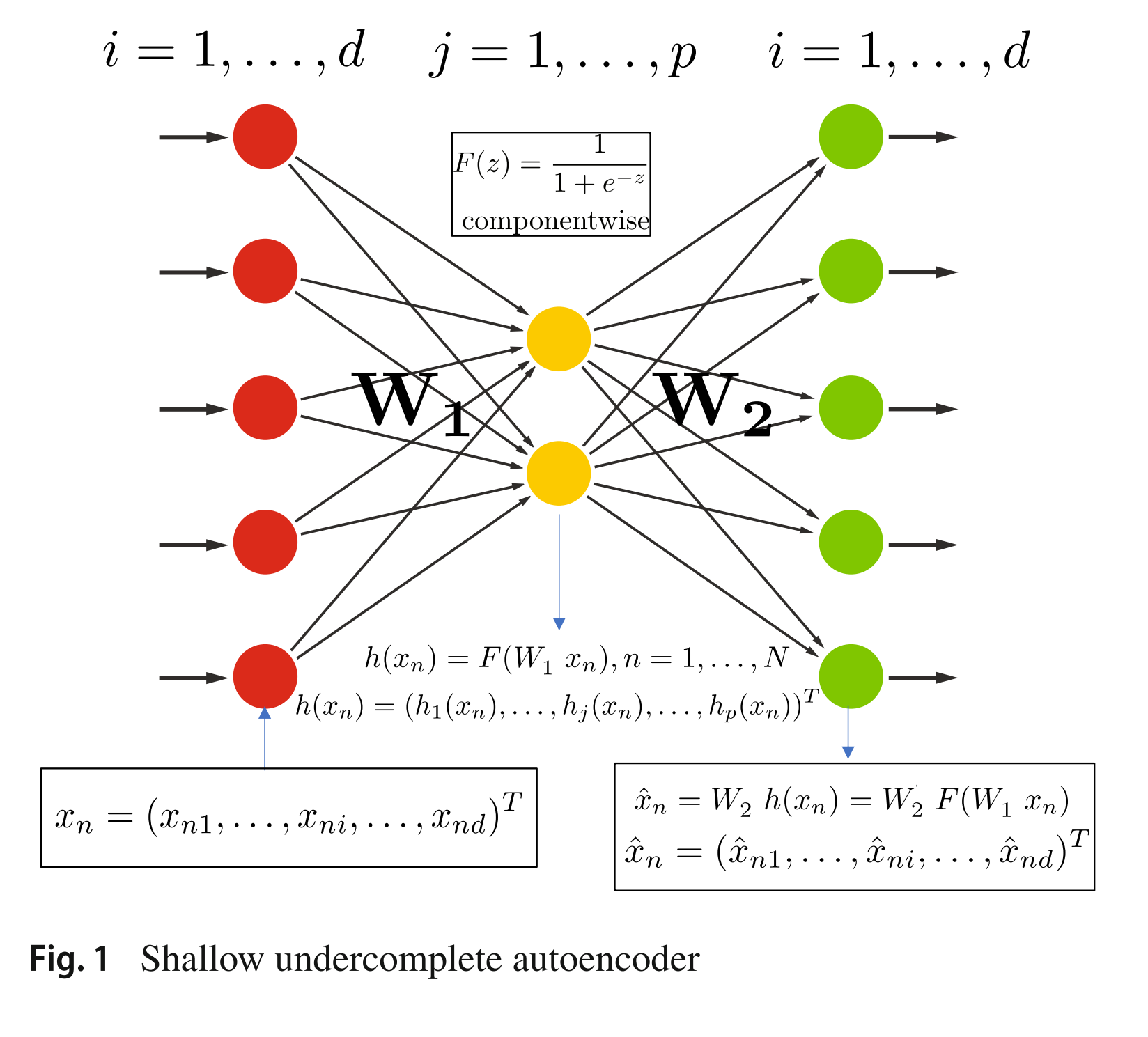
latent vector: 입력 데이터 $x \in \mathbb{R}^d$를 인코더가 변환하여 얻은 저차원 표현 벡터 $z \in \mathbb{R}^p$ ($p < d$)를 말한다. 결정론적(deterministic) AutoEncoder에서는 인코더의 선형 변환 $W_1 \in \mathbb{R}^{p \times d}$와 성분별(component-wise) 비선형 함수 $F$에 대해 $z = h(x) = F(W_1 x)$로 정의되며, 각 성분은 $z_j = F\!\left(\sum_{i=1}^{d} W_1(j,i)\, x_i\right),\ j = 1, \dots, p$ 이다. 한편 VAE에서는 $z$가 하나의 고정된 점이 아니라 확률 분포 $q_\phi(z \mid x)$에서 추출(sampling)되는 확률 변수로 취급된다. $p < d$이므로 latent vector는 원본보다 낮은 차원에서 데이터의 본질적 특징(feature)을 압축해 담고 있다.
latent space: latent vector들이 존재하는 $p$차원 공간 $\mathcal{Z} \subseteq \mathbb{R}^p$을 말한다. 인코더는 데이터 공간 $\mathcal{X} \subseteq \mathbb{R}^d$의 점을 latent space의 점(또는 분포)으로 사상(mapping)하며, $p < d$이므로 이 과정에서 차원 축소(dimensionality reduction)가 일어난다. VAE에서는 latent space 위에 사전 분포(prior) $p(z)$, 일반적으로 $p(z) = \mathcal{N}(0, I)$를 두어, 데이터의 의미적·구조적 유사성이 이 공간 안에서의 거리·위치 관계로 연속적으로 표현되도록 한다.
recognition model: encoder라고 하기도 하며, 관측된 데이터 $x$로부터 잠재 변수 $z$를 추론하는 모델이다. 확률론적으로는 사후 분포(posterior) $p(z \mid x)$의 근사인 $q_\phi(z \mid x)$로 표현되며, 보통 $q_\phi(z \mid x) = \mathcal{N}\!\left(z;\ \mu_\phi(x),\ \sigma^2_\phi(x) I\right)$ 형태의 가우시안으로 두어 인코더가 평균 $\mu_\phi(x)$와 분산 $\sigma^2_\phi(x)$를 출력하도록 한다. 여기서 $\phi$는 인코더의 파라미터이다. 결정론적 관점에서는 단순히 $z = h_\phi(x) = F(W_1 x)$로 쓸 수 있다. 데이터가 주어졌을 때 그것을 만들어냈을 법한 잠재 변수를 "인식(recognize)"한다는 의미에서 recognition model이라 부른다. ($x \to z$, 즉 $\mathcal{X} \to \mathcal{Z}$ 방향)
generation model: decoder라고 하기도 하며, 잠재 변수 $z$로부터 데이터 $x$를 복원·생성하는 모델이다. 확률론적으로는 우도(likelihood) $p_\theta(x \mid z)$로 표현되며, 여기서 $\theta$는 디코더의 파라미터이다. 결정론적 관점에서는 $\hat{x} = g_\theta(z) = W_2 z$로 쓸 수 있다. 사전 분포 $p(z)$와 결합하면 생성 과정은 $p_\theta(x, z) = p_\theta(x \mid z)\, p(z)$로 정의되며, $z \sim p(z)$를 뽑아 $p_\theta(x \mid z)$로 데이터를 만들어낸다. 잠재 변수로부터 실제 데이터를 "생성(generate)"한다는 의미에서 generation model이라 부른다. ($z \to x$, 즉 $\mathcal{Z} \to \mathcal{X}$ 방향)
두 모델을 결합하면 VAE의 학습 목표는 데이터의 주변 우도 $\log p_\theta(x)$를 직접 최대화하는 대신, 그 하한인 ELBO(Evidence Lower Bound)를 최대화하는 것으로 정리된다: $$\log p_\theta(x) \ \geq\ \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log p_\theta(x \mid z)\right] \ -\ D_{\mathrm{KL}}\!\left(q_\phi(z \mid x)\,\|\,p(z)\right).$$ 우변의 첫 항은 generation model의 재구성(reconstruction) 정확도를, 둘째 항은 recognition model이 만든 분포 $q_\phi(z\mid x)$가 사전 분포 $p(z)$에서 벗어난 정도를 측정한다. 이 ELBO를 $\phi,\theta$에 대해 동시에 최대화함으로써 recognition model과 generation model이 함께 학습된다.
다만 Gaussian likelihood에 기반한 reconstruction loss는 여러 가능한 출력을 평균내는 방향으로 작동하기 때문에, VAE 단독 모델의 출력은 흐릿해지는 경향이 있다 (3.6.2에서 자세히 다룬다). 최신 generative model은 이 약점을 보완하기 위해 VAE와 diffusion을 결합한다. VAE가 형성한 latent space 위에서 diffusion이 디테일을 점차 복원하는 구조이다. 직관적으로는, 어떤 사람을 떠올릴 때 먼저 전체적인 형태와 피부색, 이목구비 같은 큰 윤곽을 그리고(VAE의 역할), 그 흐릿한 상을 점차 선명한 상으로 다듬어 그 사람의 모습을 정확히 떠올리는 과정(diffusion의 역할)에 비유할 수 있다. Stable Diffusion이 대표적 예이다.
이후의 모든 내용은 이것들을 어떻게 VAE에 맞춰서 자리를 잡고 나아가 데이터셋의 likelihood에 대해 posterior, prior의 최적화를 달성하는지를 배울 것이다. 이러한 분야는 variational inference라 한다. 이번 강의에서는 EM, wake-sleep, ELBO & KL divergnce, free energy 기반의 최적화를 전부 살펴볼 것이다.
아래는 본격적으로 강의를 시작하기전, 각 모델의 가정이 잠재공간에 어떤 변화를 만드는지 직관적으로 시각화한 자료를 소개한다. 이 내용은 챕터의 시각화는 모든 내용을 읽고 다시 보면 깊은 이해해 도움을 줄 것이다.
본 강의에서 다룰 세 모델은 모두 encoder로 입력을 압축하여 latent space에 표현한 뒤 decoder로 복원한다. 차이는 latent space의 한 점을 어떻게 정의하느냐에 있다. 아래 그림이 그 차이를 한 장으로 요약한다. 식과 손실함수는 본 강의 진행 중 차례로 설명된다.
2.1 AutoEncoder 두가지 technic: auto-association과 information bottleneck
2.1.1 auto-association과 encoder-decoder
AutoEncoder모델들을 이해하기 위해서는 auto-association과 information bottleneck이 만드는 현상에 대해서 어느정도 이해해야한다. 앞서 수학적인 정의를 좀 더 쉽게 이야기해보자.
고전 암호학의 Caesar cipher는 사람이 직접 설계한 함수이다. JPEG의 압축 알고리즘 또한 마찬가지이며, DCT 변환, quantization table, Huffman coding 모두 공학자가 정밀히 설계한 규칙이다. 그러나 자연 이미지나 자연어처럼 패턴이 복잡한 데이터에 대해 사람이 직접 좋은 압축 규칙을 설계하기는 사실상 불가능하다. 고양이 사진의 압축 함수에는 털, 눈, 코, 자세, 조명, 배경 등 너무 많은 변수가 관여하기 때문이다.
머신러닝의 접근은 함수 자체를 데이터로부터 학습하는 것이다. Neural network은 이러한 학습 가능한 함수족(universal approximator)의 대표적 예이다. 이러한 함수 자체를 학습시키기 위해서 입력과 출력을 같이 두고 각각을 Encoder와 decoder로써 정의한다. 이후 해당 함수를 neural network으로 구성한뒤 적절한 손실 함수로 학습시킨 모델의 구조를 AutoEncoder 계열의 모델이라고 한다.
AutoEncoder는 encoder $f_\phi : \mathbb{R}^D \to \mathbb{R}^d$ ($d < D$)와 decoder $g_\theta : \mathbb{R}^d \to \mathbb{R}^D$로 구성된 neural network이며, 입력 $x$를 latent 표현 $z = f_\phi(x)$로 부호화한 뒤 다시 $\hat{x} = g_\theta(z)$로 복원한다. 학습 목표는 입력과 복원 사이의 차이를 최소화하는 것이다.
$\phi, \theta$는 각각 encoder와 decoder의 학습 가능한 파라미터(weight)이다.
Auto-association 구조에서는 입력 $x$ 자신이 정답 역할을 하므로, 입력 데이터와 타깃 데이터가 동일한 분포를 따른다. 이 덕분에 학습 목표를 수학적으로 해석하기 편하다.
2.1.2 information bottleneck
위의 Auto-association의 구조만으로는 그저 단순한 입출력일 뿐이다. 이것이 앞서 말한 encode-decord 구조로써 작동하기 위해서는 중간에 입력차원에 비해 작은 차원의 레이어를 두어야하고, 이를 이해하기 위해서는 information bottleneck에 대해서 알아야한다. information bottleneck은 표현이 담는 정보의 공간을(앞서 말한 비트) 제한함으로써, 적은 양의 표현으로도 데이터의 핵심 구조를 담아내도록 만드는 이론으로, 잠재 벡터 추출, 디노이징, 필터링 등의 목적으로 적용할 수 있다. 앞서 말한 비유에서 수는 존재하고 그 수를 표현하는 규칙을 십진수를 사용해도 소인수분해를 사용해도 그 수의 의미자체가 바뀌지는 않는다고 하였다. 그리고 이러한 수와 수를 표현하는 방식을 분리하여 분석하기 시작한 것이 현대 수학의 전환점중 하나라고 언급하였는데, AutoEncoder는 바로 이러한 진법과 같은 더 효율적인 표현방식이 알려져 있지 않을때 이를 자동으로 찾기위한 구조를 채택하여 생성모델로 테스트를 하는 것으로도 이해될수 있다. 따라서 본 강의에서는 information bottleneck을 데이터에 대한 표현으로 압축하고 복원하는 용도로 사용함을 밝힌다. 수학적으로는 Auto-association 구조에서 Encoder의 출력 차원 $d$를 데이터 입력 차원 $D$보다 작게 만들어, 학습된 잠재 특성이 데이터의 입력 차원보다 적은 수로 압축되도록 하는 것을 의미한다.
information bottleneck은 neural network에서 입력을 더 적은 차원으로 표현하도록 강제하기 위해, 입력 레이어보다 차원이 적은 중간 레이어를 둠으로써 구현한다. 이 중간 레이어의 출력을 latent code라고 하며, 이는 latent vector와 같은 것을 가리킨다. code는 정보를 압축해 부호화한 결과라는 정보이론적 관점의 용어이고, vector는 그것을 실수 성분들의 배열로 보는 선형대수적 관점의 용어로, 같은 대상을 서로 다른 관점에서 부르는 것이다. 예컨대 784개의 픽셀을 32개의 실수로 표현해야 한다면 픽셀 하나하나를 따로 저장할 수 없고, 픽셀들 사이의 통계적 의존 관계를 활용할 수밖에 없다. 이 제약이 모델로 하여금 데이터를 만드는 원리를 학습하게 만드는 메커니즘이다.
이제 수학적으로 들어가보자. information bottleneck는 입력 $X$를 압축한 표현 $T$를 찾되, 압축의 정도 $I(X;T)$는 줄이면서도 보존하고자 하는 관련 정보 $I(T;Y)$는 최대한 유지하도록 만드는 이론이다. 여기서 핵심이 되는 양은 두 확률변수가 공유하는 정보를 재는 상호정보량(mutual information)이며, 이는 KL divergence의 수학적인 의미이다.먼저 두 분포 $p$, $q$ 사이의 KL divergence(쿨백-라이블러 발산)를 정의한다. 이는 "데이터를 한 번 관측했을 때, 그것이 분포 $p$에서 왔는지 $q$에서 왔는지 구별하는 데 얼마나 도움이 되는가", 곧 한 분포가 다른 분포로부터 얼마나 떨어져 있는지를 재는 양이다. 한 관측 $w$가 주는 판별 정보를 로그 우도비 $\log\frac{p(w)}{q(w)}$로 보고, 이를 실제 분포 $p$에 대해 평균 낸 것으로 정의된다.
$$D_{\mathrm{KL}}(p \,\|\, q) = \sum_{w} p(w)\,\log\frac{p(w)}{q(w)}$$이는 분포 $p$가 기준 분포 $q$로부터 얼마나 떨어져 있는지를 재는 양으로, $p = q$일 때만 $0$이 되고 두 분포가 다를수록 커진다. 단, 일반적으로 $D_{\mathrm{KL}}(p\|q) \neq D_{\mathrm{KL}}(q\|p)$로 비대칭이므로 엄밀한 의미의 거리(metric)는 아니다. 이 비대칭성은 바깥의 평균이 한쪽 분포 $p$에 대해서만 취해지기 때문에 생기며, 특히 $q(w)$가 매우 작은데 $p(w)$는 그렇지 않은 사건에는 로그 우도비 $\log\frac{p(w)}{q(w)}$가 크게 발산하여 큰 벌점이 부과된다. 대칭적인 거리 개념이 필요하다면 $D_{\mathrm{KL}}(p\|q) + D_{\mathrm{KL}}(q\|p)$처럼 양방향을 더해 대칭화한 형태를 쓴다. 이외에도 카이제곱 divergence 등 두 분포의 차이를 재는 여러 방식이 있다. 이때 KL을 노름(norm)과 혼동하지 않도록 한다. 노름은 벡터공간의 한 원소(벡터·함수 등)를 입력으로 받아 그 크기를 재는 반면, KL은 두 분포를 입력으로 받아 둘의 차이를 잰다는 점에서 근본적으로 다르다. 한편 분포 사이의 차이를 총변동 거리처럼 노름에 기반한 거리 구조로 다루는 접근도 있어 다양한 기법을 적용할 수 있게 되지만, 이는 본 수업의 범위를 넘어가므로 독자의 몫으로 남긴다.
Mutual information $I(X;T)$는 바로 이 KL divergence를 두 변수가 서로 표현관계에 놓일지에 대한 확률 $p(x,t)$와 두 변수가 독립일 확률에 대해 $p(x)p(t)$ 거리를 측정한 것이다.
$$ I(X;T) = \sum_{x,t} p(x,t)\,\log\frac{p(x,t)}{p(x)\,p(t)} = D_{\mathrm{KL}}\!\big(\,p(x,t)\,\big\|\,p(x)p(t)\,\big) $$이것을 x를 데이터, t를 그 데이터에 대한 잠재벡터로 보면, $ p(x,t)$는 데이터와 잠재벡터가 실제로 짝지어 함께 나타나는 분포다. 반면 $p(x)p(t) $ 는 데이터와 잠재벡터를 각각 따로, 서로 무관하게 뽑았을 때의 분포로, 곧 둘이 독립이라고 가정했을 때의 결합분포다. 상호정보량은 이 실제로 엮인 분포와 독립이라 가정한 분포 사이의 거리(KL)를 재며, 둘이 멀수록 잠재벡터가 데이터와 강하게 연관되어 정보를 많이 공유함을 뜻한다.
즉 상호정보량은 "실제 결합분포$P(x,t)$가 두 변수를 독립이라 가정한 분포 $p(x)p(t) or X \perp T$ 으로부터 얼마나 벗어났는가"를 측정한다. 만약 $X$와 $T$가 완전히 독립이라면 $p(x,t) = p(x)p(t)$가 성립하여 $I(X;T) = 0$이 되고, 두 변수의 의존성이 강할수록 결합분포가 독립 가정에서 멀어져 값이 커진다. 이것이 곧 "$X$와 $T$가 정보를 얼마나 공유하는가"라는 직관과 일치한다. (연속 변수일 경우 합 대신 적분을 사용한다.)
한편, 로그 안을 $p(x,t) = p(x \mid t)\,p(t)$로 분해하면 같은 양을 엔트로피로 다시 쓸 수 있다.
$$ I(X;T) = \sum_{x,t} p(x,t)\,\log\frac{p(x \mid t)}{p(x)} = H(X) - H(X \mid T) $$여기서 $H(X) = -\sum_x p(x)\log p(x)$는 $X$의 엔트로피, $H(X \mid T) = -\sum_{x,t} p(x,t)\log p(x \mid t)$는 $T$가 주어졌을 때 $X$의 조건부 엔트로피다. 이 형태는 "$T$를 알게 되었을 때 $X$에 대한 불확실성이 얼마나 줄어드는가"를 뜻한다. 결국 KL 형태와 엔트로피 형태는 동일한 값을 서로 다른 관점에서 표현한 것으로, 전자는 '독립으로부터의 이탈'을, 후자는 '불확실성의 감소'를 강조한다. 또한 두 분포가 $x \leftrightarrow t$ 교환에 대해 대칭적이므로 $I(X;T) = I(T;X)$가 성립한다.
Mutual information의 정의를$I(X;T)$ 통해 information bottleneck은 압축에 활용하는 문제는 입력 데이터 $X$, 잠재벡터 $T$, 출력 $Y$ 사이의 분포를 가정하고, 입력-잠재벡터의 상호정보량 $I(X;T)$와 잠재벡터-출력의 상호정보량 $I(T;Y)$를 각각 항으로 삼아 정의된다. 첫째 항은 압축 비용(작을수록 좋음), 둘째 항은 보존할 관련 정보(클수록 좋음)로 두고, 압축 대비 정보 보존을 최대화하는 표현 $T$를 찾는 문제, 곧 아래 목적함수 $\mathcal{L}_{\mathrm{IB}}$를 최소화하는 문제로 정의된다.
$$\mathcal{L}_{\mathrm{IB}} = I(X;T) - \beta\, I(T;Y)$$여기서 $I(X;T)$는 작을수록 좋은 압축 비용, $I(T;Y)$는 클수록 좋은 관련 정보, $\beta > 0$는 둘 사이의 균형을 정하는 하이퍼파라미터다. 본 강의에서는 information bottleneck을 주로 잠재 벡터를 추출하기 위한 목적으로 사용하며, 이때 표현 $T$가 곧 인코더가 출력하는 잠재 벡터 $z$에 해당한다. Auto-association(오토인코더) 구조에서는 보존 대상 $Y$가 입력 $X$ 자신(복원 대상)이 되므로, $I(T;Y)$는 $X$를 복원하는 데 필요한 정보를 최대한 유지하라는 제약이 된다. 정보를 제한하는 한 가지 구체적인 방법으로 Encoder의 출력 차원 $d$를 입력 차원 $D$보다 작게 $(d < D)$ 두는 방식을 쓰며, 이렇게 학습된 잠재 벡터 $z \in \mathbb{R}^{d}$는 전체 데이터셋을 설명하는 데 필요한 특성을 입력 차원보다 적은 수로 압축해 담게 된다.
이 차원 축소가 없다면 자명한 해가 존재한다. $d \geq D$로 설정하면 손실을 $0$으로 만드는 자명한 해, 곧 $g \circ f = \mathrm{id}$가 존재한다. Encoder와 decoder가 모두 항등 함수(identity map)를 학습하기만 하면 입력이 그대로 출력으로 복사되어 손실이 $0$이 되어 버린다. 이 경우 학습된 표현이 입력 그 자체이므로 정보가 압축되거나 의미 있는 구조가 추출되지 않는다. 바로 이 자명한 해를 막고 표현이 의미 있는 구조를 담도록 강제하기 위해, 앞서 설명한 information bottleneck을 도입하여 표현 $T$가 담는 정보량 $I(X;T)$를 제한함을 정리한다.
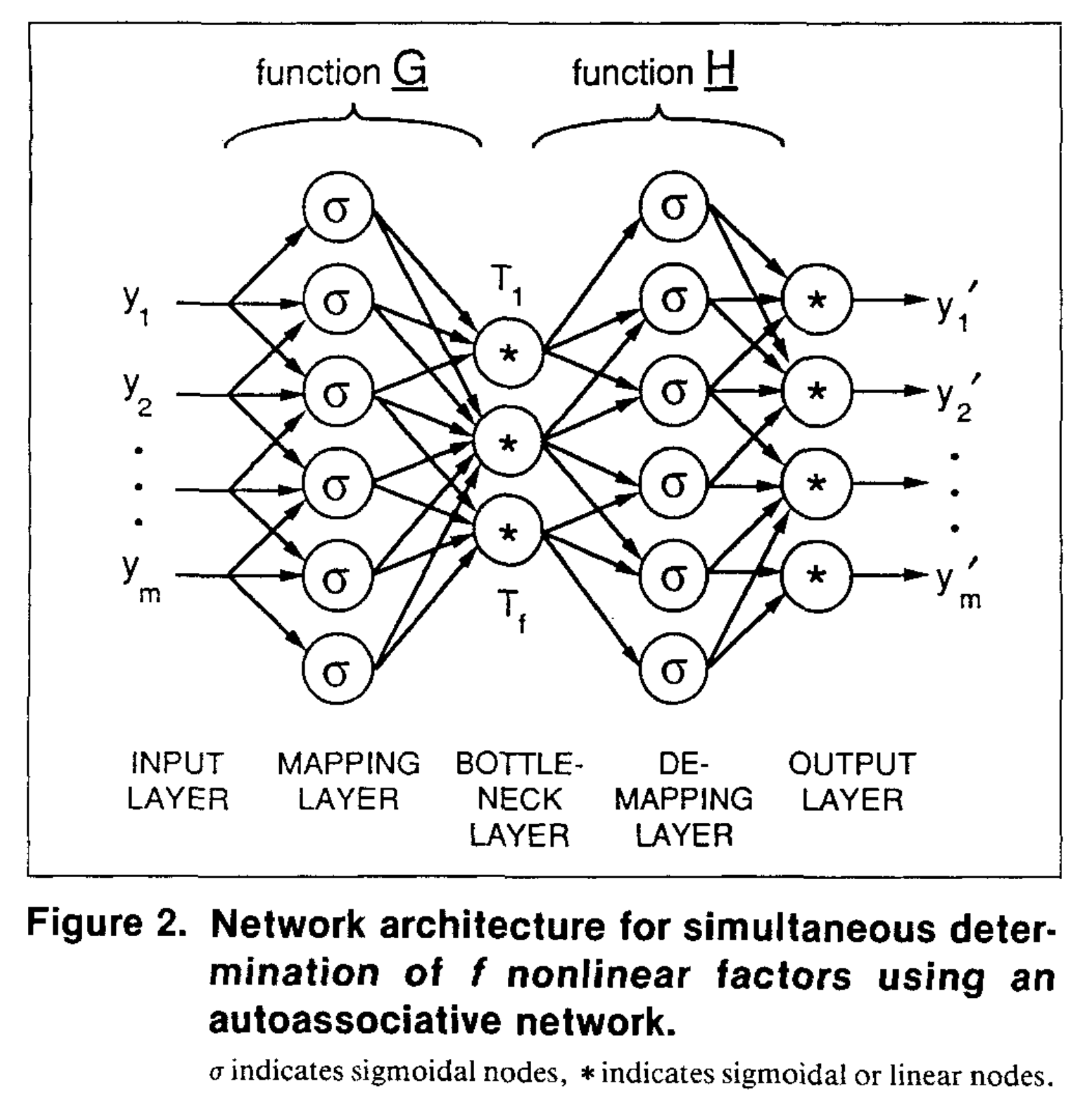
위 그림에서 가운데 information bottleneck layer가 만들어내는 벡터가 latent vector이다. 각 노드에는 시그모이드 함수나 선형 함수가 활성함수로 들어갈 수 있으며, 이렇게 활성화된 노드들 $T_1, \dots, T_f$가 모여 하나의 latent vector를 이룬다. 그리고 이러한 latent vector가 정의되는 공간이 latent space이다.
이때 latent vector는 그 자체로 데이터를 표현하는 하나의 코드인 동시에, 디코더의 기저(basis) 벡터들에 대한 계수들의 모음으로도 해석할 수 있다. 일반적인 AutoEncoder에서는 입력 전체를 하나의 전역(global) latent vector로 압축하고, 이를 디코더 기저들의 가중합으로 풀어 데이터를 복원한다. 즉 여러 잠재 요소의 합성을 하나의 통합된 벡터 안에서 다룬다. 반면 다른 모델들에서는 이러한 잠재 표현을 아키텍처 수준에서 명시적으로 분리하여, 하나의 데이터를 여러 개의 latent vector로 나누어 표현하기도 한다.
AutoEncoder의 구성요소 정리 (슬라이드에 넣기)
지금까지 이야기를 많이 했지만 autoencoder를 정리하면, 아래와 같다.
auto-association.
recognition,
generation,
activation function: 들어갈수 있는 것 간단하게 적기
latent vector: 확률 공식 으로 적기
latent space
앞으로의 모든 요소는 이 구성요소를 어떤 상황을 보고 이를 수학적으로 모델링하여 선형, 비선형 방정식이나 확률 분포를 찾아내는 알고리즘을 만드는 것이라고 할수 있다.
이처럼 어떤 상황에 대해 수학적으로 동일한 상황을 찾고 수식을 세워 상황을 가정하는것을 하며 AutoEncoder에서 수학적 모델링은 크게 결정론적 방식과 통계적 방식 2개로 나뉘어 진다.
그리고 수학적 모델링으로 인해 잠재공간이 어떻게 생기는지 이로인해 가지는 각 잠재 공간의 장점과 한계점을 돌아보며 상황에 맞는 수학적 모델링이
왜 중요한지를 앞으로의 흐름을 통해 배울수 있는 시간이 되길 바란다.
2.2 수학적 모델링을 위해 필요한 여러 구성요소들: norm 과 손실 함수: Norm에서 Gaussian과 Bernoulli까지
2.2.1 Norm: 무엇으로 오차를 잴 것인가
이제부터 본격적으로 수학적 모델링을 시작한다. 수학적 모델링을 시작하기에 앞서 몇몇 가장 중요하고 반드시 필요한 개념들을 확인하자.
첫번째로는 norm이다. 많이 들었지만 막상 의미를 물어보면 잘 대답하지 못하는 수학적 정의이기도하다. norm은 대체 무엇이고 왜 알아야할까? 이에 대한 좋은 답의 시작은 "오차의 측정이다." 언뜻 뚱딴지 같은 이 대답은 auto-association에서 어떤 구성요소의 출력과 입력간의 불일치를 어떤 방식으로 측정해야할 것인가와 같은 의미가 된다.
현실에서 길이를 잴 때는 자나 줄자를 쓴다. 그러나 ML이나 확률에서 다루는 vector나 행렬 같은 추상적 객체는 어떤 도구로 크기를 잴까? 그 답이 norm이며, 현실에서 크기에 대응되는 수학적 개념이다. 우리가 어떤 숫자나 행렬, 또는 데이터간의 어떤 크기, 또는 어떤 두 데이터간의 거리 등에 대해 ML과 수학에서는 단위가 존재하지 않는다. 대신 우리는 norm을 정의하고 이를 통해서 그 크기를 계산할수 있다. 즉, 두 점이나 벡터, 행렬 사이의 차이를 norm으로 재면 "오차의 크기"가 정의된다.
그렇기 때문에 수학에서 norm은 목적과 필요에 따라 자연스럽게 다양한 종류로 존재한다. 어떤 크기를 잴 때에는 상황에 맞는 norm, 곧 크기를 어떻게 정의할지를 적절히 선택해야 한다.
이제 ML에서 주로 언급되는 $L^2$ norm과 Frobenius norm에 대해 짧게 짚어 둔다.
$d$차원 vector $v \in \mathbb{R}^d$의 $L^2$ norm은
으로 정의된다. 기하학적으로는 원점에서 vector $v$까지의 Euclidean 거리이다. 두 vector $x, \hat{x} \in \mathbb{R}^D$의 차이의 $L^2$ norm 제곱 $\|x - \hat{x}\|_2^2 = \sum_d (x_d - \hat{x}_d)^2$이 element-wise 오차의 제곱합이다.
행렬에 대해서는 두 가지 다른 norm이 자주 등장하며 표기 충돌이 있다.
두 norm은 완전히 다른 양을 잰다. Frobenius norm $\|A\|_F$는 행렬을 한 줄로 펼친 vector에 $L^2$ norm을 적용한 것과 같으며, 모든 원소의 에너지 총합을 잰다. 반면 spectral norm $\|A\|_2$는 작용소 norm(operator norm)이며, 행렬을 linear mapping으로 보았을 때 vector를 가장 많이 늘리는 비율을 잰다. 곧 "최악의 한 방향에서의 확대율"이다.
ML 문헌에서는 Frobenius norm의 제곱을 "L2 loss"라고 부르기도 하지만, 행렬 맥락에서 $\|A\|_2$는 보통 spectral norm을 가리키므로 혼동을 피하려면 명시적으로 $\|A\|_F^2$로 적는 편이 정확하다.
Norm을 정립했으니 손실 함수를 적을 수 있다. 가장 단순한 AutoEncoder는 reconstruction의 Frobenius norm 제곱을 손실로 사용한다.
잠시 멈춰 생각해 보면, 어떻게 하면 원본 이미지와 생성 이미지의 오차를 측정할 수 있을까? 서로 다른 두 데이터 사이의 "오차"라는 개념이 얼마나 이상한 개념인지부터 생각해 보면 이 질문의 답이 하나로 결정되지 않음을 쉽게 알 수 있다. 미분방정식 교재의 1장에서 배우듯 수학적 모델링의 목표는 완벽한 무엇인가를 정의하는 것이 아니라 말이 되는, 그럴싸한 수학적 구조와 상황을 연결 짓는 것이다. 또한 생각해 본다면 두 이미지간의 오차를 픽셀로 계산한다는게 얼마나 이상한 일인지 직관적으로 이해할수 있을것이다. 보다 쉬운 이해를 위해 아래의 그림을 첨부한다. 이 기술이 시작된 1980년대의 기준에서는 두 이미지의 오차를 잰다는 개념이나, 배경/객체를 구분한다는 발상이나, 이미지라는 표현 자체가 사실상 없었음을 감안하면 단순한 모델링인 픽셀 단위 비교는 매우 합리적인 선택이었다. 그러나 픽셀 단위 비교는 fig 3. 에서 확인할수 있듯이 사람과 고양이 사람 얼굴 사이에서 사람을 구별하는 과제가 주어졌을때 당연히 사람과 고양이의 개략도가 더 유사하다고 판단하게 만들것이다.
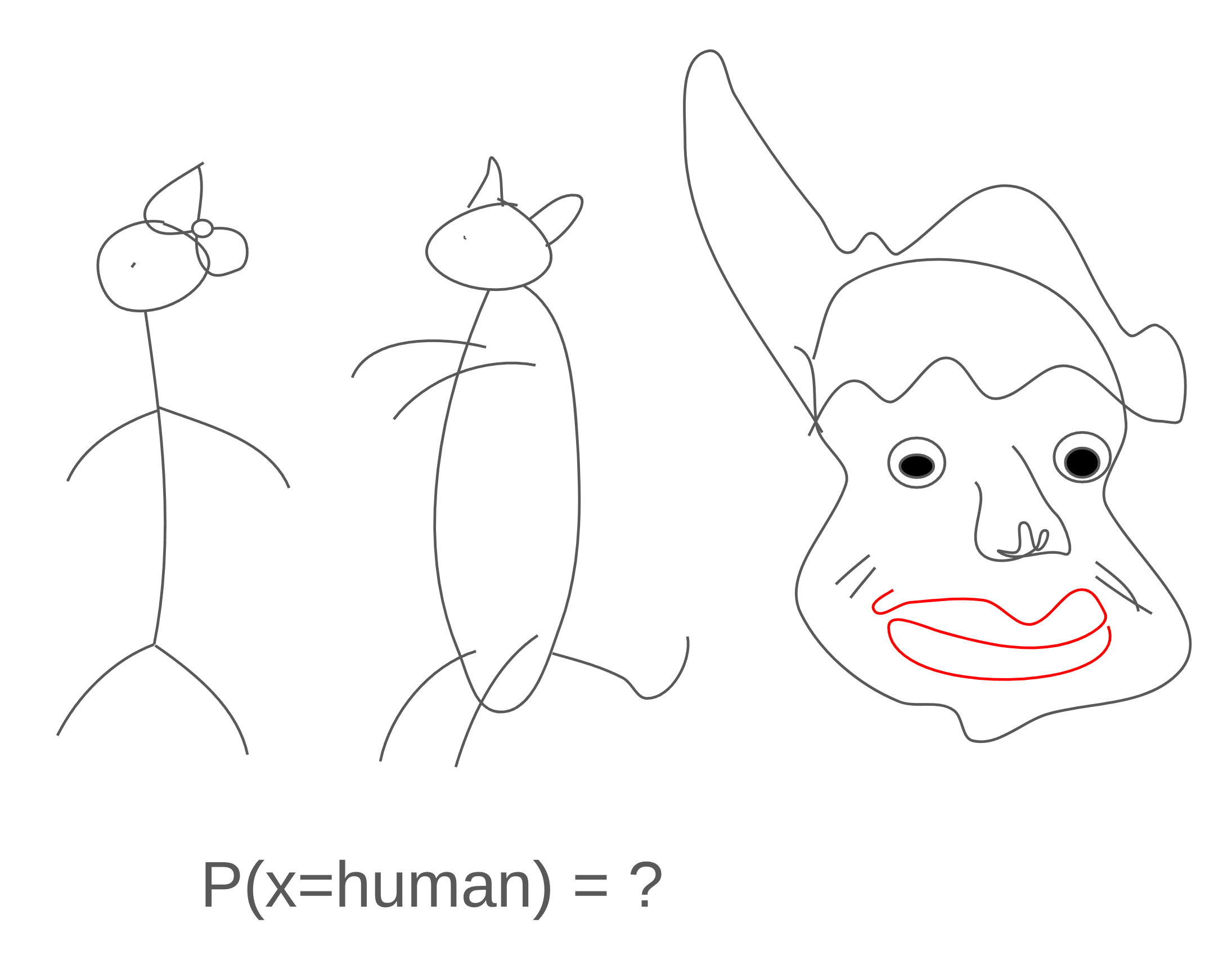
다시 돌아서와서 auto association 구조에서는 입력과 출력이 모두 같은 크기의 vector(또는 텐서)이고, 모든 원소의 오차를 균등하게 반영하고 싶기 때문에 Frobenius 제곱이 자연스러운 선택이다. 학습은 이 손실에 대한 gradient를 계산하고 $\phi, \theta$를 갱신하는 과정을 반복한다. 이 과정에서는 Gradient를 계산해도 되지만 close form의 해가 존재한다. 자세한 전개는 것은 다음 챕터에서 다루도록한다. 아니면 Gradient는 decoder 출력 $\hat{x}$에서 출발하여 decoder, latent 표현, encoder를 역순으로 거치며 backpropagation을 해도 된다.
위의 방식대로 정의된 norm과 loss로 학습된 AutoEncoder는 같은 입력에 대해 항상 같은 출력을 낸다. Encoder가 $x$를 받아 $z = f_\phi(x)$를 만들고, decoder가 $z$를 받아 $\hat{x} = g_\theta(z)$를 만들며, 같은 $x$를 두 번 넣으면 같은 $\hat{x}$가 나온다. 이러한 성질을 deterministic이라 기술한다 [13, Sec. 2.2], [14, Ch. 14]. 추후 이 deterministic 성질이 generative model 관점에서 왜 문제가 되는지를 따로 다룬다. 학습 목표는 $\hat{x}$가 $x$ 자체에 가까워지도록 만드는 것, 곧 $\hat{x} \approx x$이며, 그 가까움을 Frobenius norm으로 측정하게 된다.
2.2.2 Gaussian과 Bernoulli
이번에는 이 관점을 그대로 받아들이지 않고 좀 더 확률론적으로 유도해 본다. 먼저 encoder와 decoder를 하나로 합친 함수 $g_\theta(f_\phi(x))$를 생각하자. 지금까지는 이 함수의 출력 $\hat{x}$를 단순히 "$x$의 복원값"으로 보았다. 이제 관점을 바꾸어, $\hat{x}$를 복원값이 아니라 조건부 분포 $p(x \mid \hat{x})$를 결정하는 파라미터로 해석한다. 함수 $g_\theta(f_\phi(x))$ 여전히 입력마다 하나의 출력을 내는 결정론 함수이지만, 그 출력이 하나의 확률 분포를 지정한다고 보는 것이다. 이렇게 하였을때, AutoEncoder의 어떤 구성요소의 출력값을 선택하여 어떤 단계를 거쳐 출력값을 수렴시킬것인가를 모델링하여 결정해야한다. Gaussian과 Bernoulli각각의 확률로 모델링을 해볼수 있는 경우는 있을까? 이러한 질문에 대해 아래의 예제를 통해 고민해보자.
어떤 AutoEncoder를 자연 이미지로 학습시키려 한다. 자연이미지가 데이터와 되었을때, 입력 데이터는 이미지의 픽셀을 하나의 벡터로 쭉 늘려놓은 상태라고 하자. 이때 입력 $x \in \mathbb{R}^D$는 각 차원이 연속 실수값을 가지며, 모델은 $\hat{x} = g_\theta(f_\phi(x))$를 출력한다. 아직 손실 함수는 정해지지 않았다.
이때 다음 과정을 거쳐 손실 함수를 처음부터 설계하라.
- 모델 출력 $\hat{x}$를 "복원값"이 아니라 "$x$의 조건부 분포 $p(x \mid \hat{x})$를 정하는 파라미터"로 본다고 하자. 데이터가 연속 실수라는 점을 고려할 때, $p(x \mid \hat{x})$에 어떤 분포를 가정하는 것이 자연스러운가? 그 분포에서 $\hat{x}$는 어떤 역할(어떤 파라미터)을 맡아야 하는가?
- 고른 분포에 maximum likelihood estimation을 적용하라. 즉 $-\log p(x \mid \hat{x})$를 $D$개 차원에 대해 전개하라.
- 그 결과로부터, 파라미터 $\phi,\theta$와 무관한 항을 제거하면 어떤 손실 함수가 남는지 보여라. 이 손실이 공학적 직관으로 흔히 채택하는 손실과 같은가?
자연 이미지의 픽셀 값처럼 $x \in \mathbb{R}^D$가 연속인 경우, $\hat{x}$를 Gaussian의 mean으로 해석한다. 곧 각 차원에 Gaussian을 두며 variance를 상수 $\sigma^2$로 고정한다.
$$p(x \mid \hat{x}) = \prod_{d=1}^{D} \mathcal{N}(x_d \mid \hat{x}_d, \sigma^2), \qquad \hat{x} = g_\theta(f_\phi(x))$$각 차원의 Gaussian PDF를 풀어 적으면
$$\mathcal{N}(x_d \mid \hat{x}_d, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\!\left(-\frac{(x_d - \hat{x}_d)^2}{2\sigma^2}\right)$$$D$개 차원의 곱에 log를 취해 합으로 바꾼다.
\begin{aligned} \log p(x \mid \hat{x}) &= \sum_{d=1}^{D} \log \mathcal{N}(x_d \mid \hat{x}_d, \sigma^2) \\[4pt] &= \sum_{d=1}^{D}\!\left[-\tfrac{1}{2}\log(2\pi\sigma^2) - \frac{(x_d - \hat{x}_d)^2}{2\sigma^2}\right] \\[4pt] &= -\frac{D}{2}\log(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{d=1}^{D}(x_d - \hat{x}_d)^2 \end{aligned}차원별 제곱합 $\sum_d (x_d - \hat{x}_d)^2$이 정확히 $\|x - \hat{x}\|_2^2$이므로, 정리하면
$$\log p(x \mid \hat{x}) = -\frac{1}{2\sigma^2}\|x - \hat{x}\|_2^2 + \text{const}, \qquad \text{const} = -\frac{D}{2}\log(2\pi\sigma^2)$$const는 $\phi, \theta$에 무관한 상수이므로 학습에는 영향을 주지 않는다. 따라서 negative log likelihood $-\log p(x \mid \hat{x})$의 최소화는 $\|x - \hat{x}\|_2^2 / (2\sigma^2)$의 최소화와 같다.
이 결과는 2.2.1에서 도입한 Frobenius norm 제곱 손실과 정확히 같다 (계수 $1/(2\sigma^2)$가 붙을 뿐이며 이는 학습 최적해에 영향을 주지 않는다). 곧 공학적 직관으로 채택한 Frobenius norm 제곱 손실의 최소화는 사실은 Gaussian 분포 $p(x \mid \hat{x})$를 가정한 maximum likelihood estimation과 같다. AutoEncoder가 MSE를 사용한다는 것은 "$\hat{x}$를 Gaussian의 mean으로 모델링한다"는 가정을 깔고 있다는 의미이다.
두 번째 경우는 $x$가 0 또는 1의 이진 값을 가지는 데이터이다 (예: binarized MNIST). Bernoulli 분포로 $p(x \mid \hat{x})$를 모델링하면 negative log likelihood가 binary cross-entropy의 형태로 도출된다.
이번에는 같은 구조의 AutoEncoder를 binarized MNIST로 학습시킨다. 입력의 각 픽셀은 $x_d \in \{0,1\}$의 이진 값만 가진다. 연습문제 1에서 설계한 손실(연속 실수 가정)을 그대로 쓰면 자료형과 맞지 않는다.
다음 과정을 거쳐 이 데이터에 맞는 손실 함수를 새로 설계하라.
- 픽셀이 0 또는 1만 가진다는 점을 고려할 때, $p(x \mid \hat{x})$에 어떤 분포를 가정하는 것이 자연스러운가? 그 분포의 파라미터는 어떤 범위의 값이어야 하는가?
- 모델의 raw 출력 $g_\theta(f_\phi(x))$를 그 파라미터로 직접 쓸 수 있는가? 쓸 수 없다면 어떤 변환을 거쳐야 하며, 그 변환은 왜 필요한가?
- 고른 분포에 maximum likelihood estimation을 적용해 $-\log p(x \mid \hat{x})$를 $D$개 차원에 대해 전개하라. 최종 결과가 어떤 이름의 손실 함수와 일치하는지 밝혀라.
$x_d \in \{0, 1\}$인 경우, $\hat{\pi}$를 각 픽셀의 Bernoulli 확률로 해석한다. Bernoulli 분포의 정의는 파라미터 $\pi \in [0, 1]$에 대해
$$\text{Ber}(x \mid \pi) = \pi^x (1 - \pi)^{1 - x}, \qquad x \in \{0, 1\}$$이 식의 의미는 $x = 1$이면 $\pi$, $x = 0$이면 $1 - \pi$의 확률값을 준다는 것이다. 이를 AutoEncoder에 적용하면
$$p(x \mid \hat{\pi}) = \prod_{d=1}^{D} \text{Ber}\big(x_d \mid \hat{\pi}_d\big), \qquad \hat{\pi} = \operatorname{sigm}(g_\theta(f_\phi(x)))$$여기서 $g_\theta(f_\phi(x))$가 logit을 출력하며 sigmoid $\operatorname{sigm}(\ell) = 1/(1 + e^{-\ell})$를 씌워 $[0, 1]$ 범위의 확률로 변환한다. Standard deviation $\sigma$와의 표기 충돌을 피하기 위해 sigmoid는 $\operatorname{sigm}$으로 적는다. $D$개 차원의 곱에 log를 취해 합으로 바꾸고, 각 항의 지수를 곱셈 계수로 풀어내면
\begin{aligned} \log p(x \mid \hat{\pi}) &= \sum_{d=1}^{D} \log\!\Big[\hat{\pi}_d^{x_d} (1-\hat{\pi}_d)^{1-x_d}\Big] \\[4pt] &= \sum_{d=1}^{D}\!\Big[x_d \log \hat{\pi}_d + (1-x_d)\log(1-\hat{\pi}_d)\Big] \end{aligned}두 번째 등식에서 $\log(a^b) = b \log a$를 적용했다. 최종 식이 정확히 binary cross-entropy (BCE)의 음수 형태이다. AutoEncoder가 BCE를 쓴다는 것은 "$\hat{\pi}$를 Bernoulli의 확률 파라미터로 모델링한다"는 가정과 같다.
수치 안정성. $\log$의 인수는 데이터 $x_d \in \{0, 1\}$이 아니라 모델 출력 $\hat{\pi}_d = \operatorname{sigm}(g_\theta(\cdot)_d) \in (0, 1)$이므로 식 자체에 무한이 발생하지 않는다. $x_d$는 곱하기 계수로만 등장하므로 $x_d = 0$이면 $0 \cdot \log \hat{\pi}_d = 0$으로 첫째 항이 사라지고 둘째 항만 남는다. Sigmoid는 인수가 유한한 실수인 한 0이나 1에 도달하지 않는다. 다만 실무에서 logit이 매우 큰 양수/음수가 되면 floating-point 반올림으로 $\hat{\pi}_d$가 정확히 1 또는 0이 되어 $\log 0 = -\infty$가 나올 수 있다. 이를 피하기 위해 sigmoid와 BCE를 합친 수치 안정화 구현 (PyTorch의 BCEWithLogitsLoss 등)을 사용한다.
각 방법론의 해석과, 데이터 자료형의 관계. 정리하면 다음과 같다. 처음에는 단순하게 "입력과 출력의 오차를 픽셀별로 (또는 데이터의 각 차원별로) 제곱해 더하면 되지 않을까" 하는 공학적 관점에서 Frobenius norm 제곱을 손실로 채택했다.
그 다음에는 각 데이터 자리 (픽셀 또는 차원)를 결정하고, 그 자리에 들어올 수 있는 숫자의 field, 곧 자료형을 결정했다. 자료형이 실수인 경우는 Gaussian 분포가 자연스러우며, 그 negative log likelihood가 Frobenius norm 제곱과 정확히 일치했다. 반면 자료형이 이진 (0 또는 1)인 경우는 Bernoulli 분포가 자연스러우며, 그 negative log likelihood는 Frobenius norm 제곱과는 살짝 다른 형태 (BCE)로 나타났다.
이 두 시각의 만남이 가지는 의미는 다음과 같다. ML 모델을 다룰 때 데이터의 특성을 정확히 알지 못하면 왜 그 모델이 제대로 작동하는지를 알 수 없다. 반면 수학과 공학의 두 측면에서 동시에 접근하여 결론을 내리면, Frobenius norm 제곱은 사실 Gaussian 분포 (그리고 그와 동치인 exp 기저 PDF 가족의 일부) 에 대한 MLE의 결과로 자연스럽게 따라온다는 사실을 알게 된다. 곧 우리가 "당연하게" 채택한 손실에는 데이터가 실수값이며 한 기준 주변에서 흩어진다는 가정이 깔려 있다.
반면 자료형이 이산 (binary, categorical 등) 인 경우에는 Frobenius norm 제곱만으로는 손실을 적절히 정의하기 어렵다. 이산 자료형은 mean·variance 같은 연속 statistic으로 표현되지 않고, 그에 맞는 다른 분포 (Bernoulli, categorical 등) 의 negative log likelihood가 필요하다. 자료형이 손실 함수의 형태를 결정한다는 점이 핵심이다.
AutoEncoder: 가장 깊이 해석된 모델, 그 수학적 모델링의 역사
이전 챕터의 내용을 간단히 복습하며, 위의 예제들을 일반화하여 AutoEncoder계통의 모델의 수학적 모델링 어떻게 이뤄지는지 전체적으로 살펴보자. 이후 나올 각 방법론은 전체적으로 아래의 구조를 따르고 세부적으로 차이가 생긴다. 예를 들면, 초기의 linear AutoEncoder는 확률을 쓰지 않았고, VAE는 Helmholtz Machine모델과 동일한 구조에서 미분을 가능하게 함으로써 논문화 되었다. 즉, 전체적인 구조는 같아도 각각의 연구가 다루는 내용을 세부적으로 차이가 있으므로 그중 가장 중요하다고 생각되는 연구를 가져와 소개한다.
- 모델링하고자 하는 Sample space의 가능한 사건들을 바탕으로 적절한 입력 데이터의 형식을 결정한다.(실수나, 이산, 이진 등)
- 인코더와 디코더 모델을 하나로 합쳐 입력 데이터에 대한 조건부 확률을 likelihood로 가정한다.
- 입력 데이터의 형식에 가장 적합한 distribution familiy를 결정한다.
- likelihood를 최적화하기 위해 모델링의 해를 풀고 이를 최적화 하는 식과 단계를 바탕으로 최적해를 찾는다.
이러한 수학적 모델링을 이해하는 것은 몇 가지 장점을 준다. 첫째로, 내가 사용하려는 모델이 어떤 구조이며 어떤 데이터와 맞는지 정확하게 알 수 있다. 종종 연구자들이 체계 없이 여러 모델을 무차별적으로 대입해 보는 경우가 있다. 이런 시도도 경우에 따라서는 잘 맞을 수 있지만, 문제는 잘 되지 않았을 때다. 모델링을 이해하지 못하면 왜 잘 되지 않았는지, 그리고 도메인이 바뀌었을 때 왜 더 이상 동작하지 않는지를 쉽게 알 수 없다. 수학적 모델링을 이해하는 것은 ML을 전공으로 삼아 향후 자신의 문제에 적용하려는 이들에게 정당한 방향성을 제시해 준다.
예를 들어, 위의 모델링이 깔고 있는 가정은 다음과 같다. 데이터가 실수값이고 각 픽셀이 한 기준값 주변에서 흩어진다는 Gaussian 분포를 따른다고 가정했기 때문에, 손실은 같은 위치의 픽셀끼리만 값을 비교한다. fig 3이 보여주는 것이 바로 이 한계다. 1번과 3번은 똑같이 '사람'이지만, 1번은 전신을 작게, 3번은 얼굴을 화면 가득 그렸기 때문에 같은 자리의 픽셀을 비교하면 둘은 전혀 닮지 않았다. 오히려 1번과 2번(고양이)이 머리가 위에 달린 비슷한 전신 구도를 공유해 픽셀 단위로는 더 가깝게 측정된다. 그 결과 Frobenius norm 손실은 "사람과 고양이가, 사람과 사람보다 더 비슷하다"고 판단하게 된다.
모델링을 이해한다는 것은, 이 모델이 잘 맞을 데이터와 그렇지 않은 데이터를 미리 구분할 수 있다는 뜻이다. 픽셀 값이 실수이고 그 분포가 Gaussian 가정에 가까우며, 비교하려는 이미지들이 위치·크기 면에서 잘 정렬되어 있는 경우에는 위 모델링이 효과적으로 동작한다. 반면 fig 3처럼 같은 의미의 대상이라도 구도나 스케일이 달라지는 경우, 또는 의미적 구조가 픽셀 단위로 드러나지 않는 경우에는 이 가정이 무너지고 손실이 엉뚱한 방향을 가리키게 된다.
마지막으로 이번 장에서는 Linear AutoEncoder, PPCA, Deep AutoEncoder, Helmholtz machine 논문을 예제 형식으로 재구성한다. 각 연구가 어떤 문제 상황에서 출발했고 그 위에 어떤 수학적 가정을 세웠는지 짚어 보면서, 아키텍처가 갖는 의미를 함께 이해해 보자. 개인적으로는, 어떤 모델을 논문의 형식은 증명을 따르기 때문에 학습 용도로 작성된 글과는 구조가 다르다. 따라서 논문의 흐름을 그대로 따라가기보다 논문의 결과와 주요 쟁점을 미리 언급하고 논문이 가정한 상황을 예제 제시하여 유도과정을 풀이로 제공하는 편이 독자에게 더 빠르고 정확한 이해를 준다고 믿는다.
이러한 모델링이 어떻게 발전했는지에 대해 간단한 그림을 제공한다.
초기 AutoEncoder 계열 모델에는 확률이 도입되지 않았다. 확률 구조와 비선형성, 그리고 잠재벡터에 대한 섬세한 가정들은, 모델이 점차 수학적으로 해석되고 컴퓨팅 파워가 올라오면서 더 다양한 요구와 목적에 맞춰 진화한 결과다. 출발점인 Linear AutoEncoder는 선형을 가정한 결정론적 모델로, PCA와 동치임이 밝혀졌다. 이후 흐름은 이 PCA를 통계학의 확률 모델로 편입시키려는 시도로 이어진다. 점 추정에 불확실성을 입히고, 데이터를 생성하고 평가할 수 있는 모델로 만들기 위해서다. 그 결과가 Factor analysis의 특수 경우($\Psi = \sigma^2 I$)로 자연스럽게 유도되는 Probabilistic PCA이며, 이로써 PCA는 확률 모델로 편입되고, AutoEncoder를 확률적으로 해석하기 위한 기초가 마련되었다.
그러나 정작 AutoEncoder를 비선형 신경망 그대로 확률적으로 해석하는 일은, 통계학 계보의 PPCA가 아니라 신경망 계보에서 이뤄졌다. Hinton 교수 연구팀의 Helmholtz Machine이 그것으로, 이 모델은 통계물리학과 정보이론의 개념에 비유해 학습을 해석했고, 그 덕분에 AutoEncoder의 loss를 ML(최대우도)·자유에너지·정보이론이라는 세 관점에서 동시에 바라볼 수 있게 되었다. 이 분야의 해석이 유독 난잡해 보이는 건 이런 사연 때문이다. 연구의 흐름이 한 줄기가 아니라 여러 분야에서 해석하고 사용하며 얽혀나가며 합류했기 때문이지, 읽는 사람 탓이 아니다. (요약하면, 잘가라 대학원생 ㅋㅋㅋㅋ, 근데 그게 나네 ㅠ)
구조 좌표 지도이다. 두 축은 모델의 구조적 성질이며, 화살표는 한 성질을 더하는 구조의 변형을 뜻한다. 비선형 · 확률적 사분면에는 Helmholtz Machine과 VAE가 함께 놓이는데, 이 두 축으로는 둘이 구분되지 않기 때문이다. 둘의 차이 (학습 방법) 와 역사적 선후 관계는 시각화 01을 참조.
3.1 Linear AutoEncoder
연구자들이 모델을 어떻게 세우고 어떤 구조에 적용하며 또 어떻게 해석하는지 공부하기에 가장 단순한 형태인 linear AutoEncoder를 먼저 다룬다. 이 모델을 학습하고, 수학적으로 해석했을 때 어떤 의미를 가지는지, 그리고 왜 PCA와 일치하는지를 확인해보자. 실제 연구의 측면에서 수학적 모델링이 얼마나 섬세한 작업인지 알아보는 좋은 기회가 될 것이다.
역사적으로, 입력을 그대로 재구성하는 auto-association 구조 자체는 1986년 역전파 시대(Rumelhart-Hinton-Williams [6])에 등장했고, "선형이면 PCA와 같다"는 결과는 Bourlard-Kamp(1988) [1]가 SVD 연결로 먼저 보인 뒤 Baldi-Hornik(1989) [2]이 손실 지형 분석으로 완성했다. 오늘날 우리가 linear AutoEncoder라 부르는 것이 바로 이것이다.
3.1.1 Linear AutoEncoder의 예제
Sample covariance $\Sigma_x$가 invertible이고 eigenvalue가 모두 서로 다르다는 가정 하에, Linear AE 손실의 critical point는 다음과 같다.
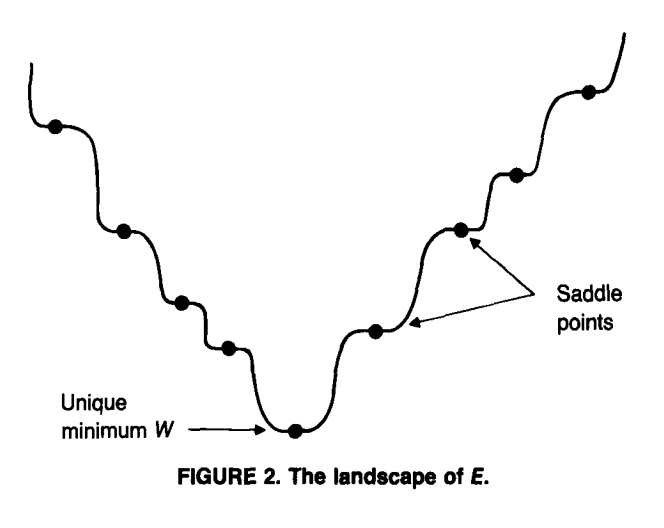
모든 critical point는 $P^\ast = U_{\mathcal{J}} U_{\mathcal{J}}^\top$ 형태이며, 여기서 $U_{\mathcal{J}}$는 $\Sigma_x$의 $d$개 eigenvector를 모은 것이다. 가능한 index 집합 $\mathcal{J}$ 중 $\mathcal{J} = \{1, \ldots, d\}$ (상위 $d$개 eigenvalue) 만이 전역 최솟값이며, 나머지는 모두 saddle point이다. Spurious local minimum은 존재하지 않는다.
가장 먼저 Linear AutoEncoder의 구성요소들을 하나씩 수학적으로 정의하자. AutoEncoder의 입력으로 어떤 센서 데이터를 가정하고, 이 센서 데이터가 실수로 구성된 $D$차원 벡터라고 하자. 이때 AutoEncoder의 구성요소는 다음과 같이 정의할 수 있다. 중요한 점은 좌표 성분들이 서로 i.i.d라고 가정하지 않는다는 것이다. 오히려 좌표들 사이의 상관관계를 covariance matrix로 측정하고, 그 구조를 이용해 PCA와의 연결을 보일 것이다.
| 구성요소 | 수학적 기호 | 의미 |
|---|---|---|
| 입력 데이터 | $x\in\mathbb{R}^D$ | 하나의 sample을 나타내는 column vector |
| 출력 데이터 | $y\in\mathbb{R}^D$ | Auto-associative 가정에 의해 목표 출력은 $y=x$ |
| 입력 layer | $x$ | Linear AE에서는 입력 데이터 자체와 구분하지 않는다. |
| hidden layer | $z\in\mathbb{R}^d$ | 입력을 압축한 latent vector이며, $d<D$가 bottleneck 조건이다. |
| 출력 layer | $\hat{x}\in\mathbb{R}^D$ | decoder를 거쳐 복원된 입력의 추정값 |
| encoder | $W_e\in\mathbb{R}^{d\times D}$ | 입력 layer에서 hidden layer로 가는 linear transformation, $z=W_ex$ |
| decoder | $W_d\in\mathbb{R}^{D\times d}$ | hidden layer에서 출력 layer로 가는 linear transformation, $\hat{x}=W_dz$ |
| global map | $P=W_dW_e\in\mathbb{R}^{D\times D}$ | 입력에서 복원값으로 가는 전체 linear map, $\hat{x}=Px$ |
$d<D$이면 hidden layer의 차원이 입력 차원보다 작다. 따라서 $W_dW_e$의 rank는 최대 $d$이고, 모든 정보를 그대로 통과시키는 identity map이 될 수 없다. Linear AE는 이 제한 안에서 reconstruction error가 가장 작아지도록 $d$차원 부분공간을 선택한다.
이제 데이터에 아래의 관례적인 통계학적 가정을 전제한다. 데이터 $\{x_1,\ldots,x_N\}\subset\mathbb{R}^D$가 centered되어 있다고 가정한다. 곧 평균이 $0$이다.
Centered가 아닌 데이터는 각 $x_i$에서 평균 $\bar{x}$를 빼면 centered로 만들 수 있으므로, 이 가정은 일반성을 크게 해치지 않는다. Centered 가정을 하는 이유는 데이터가 centered되었을 때 covariance matrix가 좌표 벡터들 사이의 inner product로 표현되기 때문이다. 이 점이 PCA의 spectral 분석과 Linear AE의 reconstruction loss를 연결하는 출발점이 된다.
Centered 데이터에 대해 covariance matrix는 다음과 같이 정의된다.
이 행렬의 $(j,k)$ 성분을 풀어 보면 데이터의 $j$번째 좌표와 $k$번째 좌표 사이의 관계를 재는 양이다.
이 양은 두 좌표 성분을 길이 $N$의 벡터 $\mathbf{c}_j=(x_{1,j},\ldots,x_{N,j})$, $\mathbf{c}_k=(x_{1,k},\ldots,x_{N,k})$로 보았을 때의 inner product를 $N$으로 나눈 것과 정확히 같다.
곧 covariance matrix의 각 성분은 데이터 좌표들 사이의 inner product이다. 데이터가 centered되어 있다는 조건이 핵심이다. centered가 아니면 위 양은 평균의 곱만큼 어긋나 covariance와 일치하지 않는다. 대각 성분 $(\Sigma_x)_{jj}=\frac{1}{N}\|\mathbf{c}_j\|^2$는 $j$번째 좌표의 variance이고, 두 좌표가 uncorrelated, 즉 $(\Sigma_x)_{jk}=0$이라는 것은 두 좌표 벡터가 직교한다는 의미이다.
$\Sigma_x$는 정의상 대칭이며, 임의의 벡터 $v$에 대해 $v^\top\Sigma_xv=\frac{1}{N}\sum_i(v^\top x_i)^2\geq0$이므로 positive semi-definite이다. 이 두 성질이 다음 절들의 spectral 분석의 출발점이다.
이제 Linear AE의 critical point를 Baldi와 Hornik [2]의 원논문 흐름대로 분석한다. 선형대수에 익숙하지 않은 독자는 결과 박스만 가져가도 무방하다.
이하 분석 전체는 입력과 출력이 같은 auto-associative case에 한정된다. 원논문은 일반 input $X\ne Y$ 케이스도 다루지만, AutoEncoder는 입력 자기 자신을 복원하는 모델이므로 자연스럽게 이 단순화에 해당한다.
3.1.2 Loss 설정
Encoder와 decoder가 activation function 없이 linear transformation만으로 구성된 경우를 다룬다. 입력 $x\in\mathbb{R}^D$, 잠재 차원 $d<D$, encoder $W_e\in\mathbb{R}^{d\times D}$, decoder $W_d\in\mathbb{R}^{D\times d}$로 두고 손실은 sample별 $\ell^2$ 제곱의 평균이다.
두 행렬의 곱을 $P:=W_dW_e\in\mathbb{R}^{D\times D}$로 적는다. 이는 아래의 의미로 해석된다.
$P$는 항상 rank deficient이다. $W_e$의 rank가 최대 $d$이고 $W_d$의 rank도 최대 $d$이므로 $P$의 rank는 최대 $d<D$이다. $D\times D$ 행렬이면서 rank가 $D$보다 작은 행렬이다. 원논문도 명시한다.
분해의 모호성. 임의의 invertible $d\times d$ 행렬 $C$에 대해 $W_dW_e=(W_dC)(C^{-1}W_e)$이므로, $W_d\to W_dC$와 $W_e\to C^{-1}W_e$로 동시에 바꿔도 곱 $P$는 보존된다. 곧 두 행렬 각각은 유일하게 결정되지 않으며, 손실에 영향을 주는 양은 곱 $P$뿐이다.
분석에는 앞에서 정의한 covariance matrix $\Sigma_x=\frac{1}{N}\sum_i x_ix_i^\top$를 사용한다. 본 절은 원논문을 따라 $\Sigma_x$가 invertible, 즉 positive definite라고 가정한다. 이 가정은 데이터가 $D$차원 공간의 어떤 방향도 완전히 잃지 않는다는 의미이다. $N<D$처럼 covariance가 rank deficient인 경우는 별도의 분석이 필요하며, 여기서는 기본 결과를 명확히 보기 위해 다루지 않는다.
3.1.3 Loss를 covariance의 trace form으로 바꾸기
AutoEncoder의 목표는 각 입력 $x_i$를 다시 자기 자신으로 복원하는 것이다. 따라서 하나의 sample에 대한 reconstruction error는 다음과 같다.
이제 sample들을 column으로 모은 데이터 행렬을 정의한다.
그러면 $(I-W_dW_e)X$의 $i$번째 column은 정확히 $(I-W_dW_e)x_i$이다. 따라서 모든 column의 제곱 길이를 더한 값, 즉 Frobenius norm의 제곱이 sample별 reconstruction error의 합과 같다.
Frobenius norm은 $\|M\|_F^2=\operatorname{tr}(MM^\top)$로 쓸 수 있다. 여기서 $M=(I-W_dW_e)X$로 두면
이 trace form이 중요한 이유는 loss가 개별 sample이 아니라 covariance $\Sigma_x$를 통해 표현되기 때문이다. 즉 Linear AE가 최소화하는 reconstruction error는 데이터가 어느 방향으로 많이 퍼져 있는지, 다시 말해 variance 구조와 직접 연결된다. 이 연결 덕분에 이후에는 “오차 최소화” 문제를 “큰 variance를 가진 방향을 보존하는 문제”로 바꿀 수 있다.
3.1.4 Fact 1: $W_d$ 고정 시 $W_e$의 최적해
$W_d$를 고정하고 $W_e$에 대해 손실을 미분한다. Trace form을 전개하면 $W_e$에 의존하는 항을 다음처럼 볼 수 있다.
따라서 $W_e$에 대한 gradient는 다음과 같다.
이를 $0$으로 두면 critical point 조건
를 얻는다. 여기서 $\Sigma_x$가 invertible이므로 양변의 오른쪽에 $\Sigma_x^{-1}$을 곱할 수 있다.
이제 $W_d$가 column full rank이면 $W_d^\top W_d$가 invertible이므로 unique한 해를 얻는다.
이는 $W_d$의 Moore-Penrose left inverse와 정확히 일치한다. 직관적으로 말하면 decoder $W_d$가 펼치는 subspace가 먼저 정해졌을 때, encoder는 입력을 그 subspace 위의 좌표로 가장 잘 되돌려 주는 역할을 한다.
3.1.5 Fact 3: critical point에서 $P$의 형태
Fact 1을 대입하면 critical point에서 전체 map $P$가 다음 형태이다. P의 의미는 인코더와 디코더의 곱으로 이는 두
이 행렬은 두 가지 성질을 만족한다.
대칭성. $W_d^\top W_d$가 symmetric이면 그 inverse도 symmetric이다. 따라서
멱등성. $M:=W_d^\top W_d$로 두면
대칭이면서 멱등인 행렬은 그 image로의 orthogonal projection이다. 곧 $P^\ast$는 $W_d$의 column space로의 orthogonal projection이다.
$W_d$를 고정하고 $W_e$를 최적으로 고르면 Linear AE의 전체 map은 임의의 rank-$d$ linear map이 아니라, $W_d$의 column space라는 어떤 $d$차원 subspace로의 orthogonal projection이 된다. 따라서 남은 문제는 “$W_e$와 $W_d$의 모든 entry를 어떻게 고를 것인가”가 아니라, 어떤 $d$차원 subspace를 선택할 것인가이다.
3.1.6 전역 최솟값: PCA subspace가 선택된다
이제 $P$가 어떤 $d$차원 subspace $S$로의 orthogonal projection이라고 하자. 그러면 $P^\top=P$이고 $P^2=P$이다. 따라서 $I-P$도 symmetric이고 idempotent이다. Trace의 cyclic property를 쓰면 loss는 다음과 같이 정리된다.
$\operatorname{tr}(\Sigma_x)$는 데이터의 총 variance이므로 상수이다. 따라서 reconstruction error를 최소화하는 것은 $\operatorname{tr}(P\Sigma_x)$, 즉 projection 후 보존되는 variance를 최대화하는 것과 같다.
$\Sigma_x=U\Lambda U^\top$로 eigendecomposition하고 $\Lambda=\operatorname{diag}(\lambda_1,\ldots,\lambda_D)$, $\lambda_1\ge\lambda_2\ge\cdots\ge\lambda_D\ge0$라 하자. 각 eigenvector $u_j$가 projection subspace에 얼마나 포함되는지를
로 정의하면 $0\le\rho_j\le1$이고 $\sum_j\rho_j=\operatorname{tr}(P)=d$이다. 또한
이다. 따라서 보존 variance는 큰 eigenvalue에 더 많은 weight가 실릴 때 커진다. 이 값은 상위 $d$개 eigenvalue에 weight $1$을 주고 나머지에 $0$을 줄 때 최대가 되며, 실제로 그 값은 다음 projection으로 달성된다.
이때 최소 loss는 선택하지 못한 eigenvalue들의 합이다.
Linear AE의 전역 최적해는 covariance $\Sigma_x$의 상위 $d$개 eigenvector가 span하는 subspace로의 orthogonal projection이다. 이것이 PCA의 principal subspace와 정확히 같다. 따라서 Linear AE는 PCA와 같은 부분공간을 학습한다고 말할 수 있다. 다만 latent coordinate basis 자체가 PCA basis와 동일하게 고정되는 것은 아니다.
3.1.7 Critical point와 saddle point
Baldi-Hornik의 분석은 전역 최적해뿐 아니라 loss surface의 critical point 구조도 설명한다. Projection $P$가 critical point가 되려면, subspace를 아주 조금 회전시켰을 때 1차 변화가 없어야 한다. 이 조건은 다음 commute 관계로 정리된다.
$\Sigma_x$의 eigenvalue가 모두 서로 다르면, $\Sigma_x$와 commute하는 orthogonal projection $P$는 $\Sigma_x$의 eigenvector들 중 일부를 고르는 projection이어야 한다. 즉 어떤 index 집합 $\mathcal{J}\subset\{1,\ldots,D\}$, $|\mathcal{J}|=d$에 대해
꼴이 된다. 이때의 loss는 다음과 같다.
$\mathcal{J}=\{1,\ldots,d\}$인 경우만 전역 최솟값이다. 그 외의 선택에서는 어떤 $j\in\mathcal{J}$보다 큰 eigenvalue를 가진 $i\notin\mathcal{J}$가 존재한다. 이때 subspace를 $u_j$ 방향에서 $u_i$ 방향으로 아주 조금 회전시키면 보존 variance가 증가하고 loss가 감소한다. 반대로 다른 방향으로는 loss가 증가할 수 있으므로 이런 critical point는 local minimum이 아니라 saddle point이다.
Linear AE의 loss surface에는 spurious local minimum이 없다. 전역 최솟값은 PCA의 상위 principal subspace에 대응하고, 나머지 critical point는 모두 saddle point이다.
3.1.8 학습된 표현과 latent ambiguity
실용적인 관점에서 잘 학습된 AutoEncoder는 $D$차원 입력을 $d$차원으로 압축한다. MNIST의 경우 784차원이 32차원 정도로 줄어도 의미 있는 복원이 가능하다. 또한 같은 클래스의 데이터가 latent space에서 가까이 모이는 군집 구조가 자연스럽게 형성될 수 있으며, 학습된 $z$는 classification, clustering 등 후속 task의 입력으로 활용될 수 있다.
그러나 Linear AE가 PCA와 같다고 할 때 가장 조심해야 할 부분이 있다. 전역 최적해에서 결정되는 것은 projection $P^\ast$ 또는 principal subspace이지, encoder와 decoder의 구체적인 basis는 아니다. 실제로 임의의 invertible matrix $C\in\mathbb{R}^{d\times d}$에 대해
로 새 한 쌍을 만들어도
이므로 reconstruction loss는 변하지 않는다. 하지만 latent code는 달라진다.
특히 latent의 covariance도 $C$에 따라 달라진다.
곧 학습은 $W_d$의 column space, 즉 부분공간을 결정하지만, 그 안의 coordinate axis는 추가 제약 없이는 결정하지 않는다. 따라서 “Linear AE가 PCA의 principal components를 그대로 출력한다”고 말하기보다는, “Linear AE가 PCA의 principal subspace를 학습한다”고 말하는 편이 정확하다.
3.2 Probabilistic PCA: Linear AE의 확률 모델
시작전에 전체적인 그림을 훑어보자면, Probabilistic PCA(PPCA)는 고전적인 PCA에서 잠재변수와 확률을 도입해 재해석한 모델이다. 기존 PCA는 주성분 부분공간, 즉 eigenvector가 span하는 subspace를 찾는 방법이다. 따라서 이것을 통계학에서 사용하기 위해서는 데이터가 어떤 잠재요인으로부터 어떤 확률분포를 통해 생성되었는지를 명시적으로 설명하게끔 해야했다. 특히, 이 시기 통계학에서는 Factor Analysis처럼 관측 데이터 뒤에 존재하는 잠재변수와 그 확률분포를 통해 전체 데이터 분포를 설명하려는 흐름이 있었고, PPCA는 Factor Analysis를 PCA에 잠재 변수를 명시적으로 가정하고 현재 입력 데이터가 어떤 잠재 벡터에 대한 조건부 확률로 두어 이것이 가우시안 확률 모델의 분포를 따른다고 가정했다. 구체적으로 PPCA는 latent variable \(z\)에 Gaussian prior를 두고, decoder를 \(z\)의 선형 변환과 Gaussian noise로 정의한다. 이 점에서 PPCA는 PCA의 확률적 버전이면서, 제곱 재구성 오차를 최소화하는 Linear AutoEncoder가 PCA의 주성분 부분공간과 동치라는 사실과도 자연스럽게 연결된다. PPCA에서는 선형-가우시안 구조 덕분에 decoder에 해당하는 생성행렬의 maximum likelihood 해가 공분산 행렬의 고유분해로 명시적으로 주어지고, encoder에 해당하는 posterior \(p(z \mid x)\) 역시 Gaussian 형태로 닫힌 해를 가진다. 다만 데이터 차원 \(D\)가 커지면 공분산 행렬을 구성하고 \(D \times D\) 고유분해를 수행하는 비용이 커지므로, 잠재 차원 \(q\)가 훨씬 작을 때는 EM 알고리즘을 사용해 같은 ML 문제를 반복적으로 푸는 방식이 계산적으로 더 효율적일 수 있다. 따라서 PPCA에서 EM은 posterior가 닫히지 않아서 사용하는 근사추론이 아니라, 명시적 해가 존재하는 선형-가우시안 모델을 더 효율적으로 추정하기 위한 계산적 대안으로 이해하는 것이 정확하다. 이후 VAE의 관점에서 보면, Gaussian latent variable과 Gaussian decoder를 사용하되 decoder를 선형으로 제한한 경우 PPCA와 밀접하게 대응되므로, PPCA는 VAE로 넘어가기 전 이해해야 할 가장 단순한 선형 생성모델로 볼 수 있다.
3.2.1 PPCA 예제
다음의 챕터로 넘어가기기전에 기본적인 통계학의 수학적 표현의 정의에 대해서 정리한다. 동전 던지기나 여러 이산적인 량을 다루는 사건에서 $P(X=x) = f_X(x)$ 이러한 표기를 자주 봤을수 있다. 이는 Discreate random variable이라 하며, 이산적인 사건에서만 가능하다. $\sum_X f_X(x) = 1인 f_X(x)$를 PMF라 한다. 반면 연속적인 random variable에서는 $F_X(x) = \int_{-\infty}^x f_X(t)dt$인 $F_X(x)$에 대해 $P(a < X < b) = F_X(b) - F_X(a),(b>a) = \int_a^b f_X(t) dt$로 정의된다. $\int_{\-infty}^{\infty} f_X(t) dt = 1인 f_X(t)$를 pdf라고한다. 그리고 $F_X(x) = F_X(x) = \int_{-\infty}^x f_X(t)dt = P_X(X \leq x) $인 $F_X(x)$를 cdf라고 한다. 그림 -> CDF, PDF, PMF등 설명 아마 ML을 하며 이 식은 익숙할 독자들이 많다. 그러나 의외로 P(X=x)의 정확한 정의에 대해서 물어보면 모르는 사람이 많다. 따라서 P(X=x)에 대해서 정의한다. 어떤 사건들에 대한 집합을 SampleSpace $\Omega$라고 정의하자. 그러면 를 실수 공간으로 보내는 함수를 X라 하고$ X:\Omega -> \mathcal{R}$이라고 한다. 이때의 함수X를 random variable 라고 하며, 다음과 같이 표기한다. $X = {w \in \Omega : X(w) }$ 또한 해당 함수를 아래와 같이 표기하는것은 다음의 의미를 가진다. X(Head) = 1, X(Tail) = 0. 따라서 X는 어떤 상태 w를 읽어 값 X(w)로 해석하는 함수이다. 그러나 이러한 X가 어떤 상태가 몇개 있는지 확률을 측정하기 위한 함수 P를 정의해야한다. P와 함께 X는, $P(X=1) = P({w:X(w) = 1})$의 단순한 표기이며, 따라서 X는 확률을 주는 것이 아니며, P가 그것을 확률로 측정하는 함수이다. 이러한 함수를 Meaure function이라고 한다.
확률변수 $X$는 그 값마다 사건 $A_x = \{\omega : X(\omega) = x\}$를 만들고, 이 사건들이 서로 겹치지 않으면서 합치면 표본공간 전체가 되어 $\Omega$의 분할(partition)을 이룬다. partition이란 표본공간 $S$를 다음을 만족하도록 나눈 것이다.
$$X_i \cap X_j = \emptyset \ (i \neq j), \qquad \bigcup_i X_i = S, \qquad X_i \neq \emptyset$$한편 데이터 $X$와 잠재벡터 $Z$처럼 두 확률변수가 함께 있을 때, 한쪽에서 다른 쪽으로 가는 방향을 조건부분포로 나타낼 수 있고, 두 방향은 베이즈 정리로 엮인다.
$$p(z \mid x) = q(x \mid z)\,p(z) / p(x)$$ ~~ 여기 피드백 필요.3.2.1 PPCA 예제
3.2.2 PPCA의 모델 가정 정리
가장 먼저 PCA에 확률을 도입하기 위해서 힌트에 제시된 linear factor analysis의 식을 사용하기 위한 용어를 먼저 정의한다. 입력할 데이터가 PCA가 적용이 가능할때 입력데이터는 어떤 잠재 벡터들에 대해 평균이 0인 가우스 분포 모델의 형태를 따른다고 가정하자. 분포에 대한 지식이 있다면 어렵지 않게 이 가정이 매우 이상함을 알수 있다. 그러나 통계학에서 자연적인 사건들은 주로 가우스분포를 따르므로 그러한 모델에 대해서 잘 적용되는 모델이라고 보면 이는 타당한 가정이다. 가능한 여러 분포모델이 있을수 있지만, 여기서는 가우스 분포모델을 사용한다. 가우스 분포모델에서는 $\mu,\sigma$정보를 알면 확률밀도함수를 확정 지을수 있다. 이때 PPCA는 입력데이터에 대해 centered 가정을 하지 않는다. 따라서 각 잠재 벡터를 기저로 설명하고 대각행렬로 표현하면 모든 구성 요소를 아래와 같이 정리할수 있다.
3.2.3 PPCA 구성요소 정리
| 구성요소 | 수학적 기호 | 의미 |
|---|---|---|
| 입력 데이터 | $x\in\mathbb{R}^D$ | 하나의 sample을 나타내는 column vector |
| 출력 데이터 | $y\in\mathbb{R}^D$ | Auto-associative 가정에 의해 목표 출력은 $y=x$ |
| 입력 layer | $x$ | PCA에서는 입력 레이어가 없다. |
| hidden layer | $z\in\mathbb{R}^q$ | PCA에서는 이것은 잠재벡터 z의 차원으로 간주한다. |
| 출력 layer | $\hat{x}\in\mathbb{R}^D$ | decoder를 거쳐 복원된 입력의 추정값 |
| encoder | $W^T\in\mathbb{R}^{q\times D}$ | 입력 layer에서 hidden layer로 가는 linear transformation, $z=W_ex$ |
| decoder | $W\in\mathbb{R}^{D\times q}$ | PCA에서 디코더는 인코더의 전치행렬으로 정의되어 있다. |
| global map | $P=WW^T\in\mathbb{R}^{D\times D}$ | 입력에서 복원값으로 가는 전체 linear map, $\hat{x}=Px$ |
위의 요소를 통해 아래의 식들을 전개한다. 우선 잠재벡터는 서로 독립이고, 잠재 벡터들이 모여 어떤 잠재 공간을 형성한다고 가정 하면, Linear AutoEncoder에서 보였던 $P =W_eW_d$가 full rank임에 대한 가정과 $z=W^T*(x-\bar{x})$ 그대로 불러올수 있다. 이는 잠재벡터가 곧 인코더와 입력 데이터가 평균에서 떨어진 정도의 곱으로 구성됨을 의미한다. 또한 잠재벡터가 가우스 정규분포를 따른다고 할때
이제 이로부터 norm을 계산해야 한다.
PPCA에서 log likelihood를 사용하는 이유를 이해하려면 먼저 조건부 생성 확률 \(p(x \mid z)\)를 보면 된다. PPCA는 latent variable \(z\)가 주어졌을 때 관측 데이터 \(x\)가 선형 decoder \(Wz+\mu\) 주변에서 Gaussian noise를 통해 생성된다고 가정한다. 즉, 모델은 다음과 같다.
$$ z \sim \mathcal{N}(0, I) $$ $$ x \mid z \sim \mathcal{N}(Wz+\mu, \sigma^2 I) $$따라서 어떤 latent \(z\)가 주어졌을 때 데이터 \(x\)가 생성될 확률은 다음의 Gaussian likelihood로 표현된다.
$$ p(x \mid z) = \frac{1}{(2\pi\sigma^2)^{D/2}} \exp\left( -\frac{1}{2\sigma^2} \|x-\mu-Wz\|^2 \right) $$여기서 \(D\)는 데이터의 차원이고, \(\|x-\mu-Wz\|^2\)는 실제 데이터 \(x\)와 decoder가 복원한 값 \(Wz+\mu\) 사이의 제곱 오차이다. 즉, 이 노름은 reconstruction error를 의미한다. Gaussian likelihood는 이 reconstruction error가 작을수록 큰 값을 가지며, error가 커질수록 지수적으로 작아진다.
이 likelihood를 그대로 최대화해도 되지만, 지수함수와 확률값의 곱이 포함되어 있어 계산이 불편하다. 그래서 likelihood에 log를 취한 log likelihood를 최대화한다. log 함수는 단조증가 함수이므로 likelihood를 최대화하는 해와 log likelihood를 최대화하는 해는 같다.
$$ \arg\max_{\theta} p(x \mid z;\theta) = \arg\max_{\theta} \log p(x \mid z;\theta) $$실제로 위의 Gaussian likelihood에 log를 취하면 지수함수가 사라지고 다음과 같이 정리된다.
$$ \log p(x \mid z) = -\frac{D}{2}\log(2\pi\sigma^2) - \frac{1}{2\sigma^2} \|x-\mu-Wz\|^2 $$여기서 첫 번째 항은 Gaussian normalization term이고, 두 번째 항이 reconstruction error에 해당한다. 따라서 Gaussian likelihood를 최대화한다는 것은 결국 \(\|x-\mu-Wz\|^2\)를 작게 만드는 것과 직접적으로 연결된다. 이 때문에 PPCA의 확률적 학습 문제는 PCA나 Linear AutoEncoder에서 보았던 제곱 재구성 오차 최소화 문제와 자연스럽게 이어진다.
데이터가 하나가 아니라 \(N\)개 있을 때는 전체 likelihood가 각 데이터 likelihood의 곱으로 표현된다.
$$ p(X \mid Z) = \prod_{n=1}^{N} p(x_n \mid z_n) $$여기에 log를 취하면 곱이 합으로 바뀐다.
$$ \log p(X \mid Z) = \sum_{n=1}^{N} \log p(x_n \mid z_n) $$따라서 전체 conditional log likelihood는 다음과 같이 쓸 수 있다.
$$ \log p(X \mid Z) = \sum_{n=1}^{N} \left[ -\frac{D}{2}\log(2\pi\sigma^2) - \frac{1}{2\sigma^2} \|x_n-\mu-Wz_n\|^2 \right] $$이 식에서 볼 수 있듯이 log likelihood를 취하면 전체 데이터에 대한 확률의 곱이 각 데이터에 대한 log probability의 합으로 바뀌고, Gaussian likelihood 안의 지수함수가 사라지면서 제곱 노름 형태의 reconstruction error가 명시적으로 드러난다. 이것이 PPCA에서 log likelihood를 사용하는 첫 번째 이유이다.
다만 더 엄밀히 말하면, PPCA에서 실제로 최대화하는 것은 \(p(x \mid z)\)가 아니라 latent variable \(z\)를 적분해서 제거한 marginal likelihood \(p(x)\)이다. 왜냐하면 실제 데이터에서는 각 \(x\)에 대응되는 latent \(z\)를 직접 관측할 수 없기 때문이다.
$$ p(x) = \int p(x \mid z)p(z)\,dz $$PPCA는 선형-Gaussian 모델이기 때문에 이 적분도 닫힌 형태로 계산된다. 그 결과 \(x\)의 marginal distribution은 다음과 같은 Gaussian이 된다.
$$ p(x) = \mathcal{N}(x \mid \mu, C) $$ $$ C = WW^\top + \sigma^2 I $$따라서 PPCA의 실제 log likelihood는 다음과 같이 쓴다.
$$ \log p(X) = \sum_{n=1}^{N} \log \mathcal{N}(x_n \mid \mu, C) $$이를 정리하면 다음과 같은 형태가 된다.
$$ \log p(X) = -\frac{N}{2} \left[ D\log(2\pi) + \log |C| + \mathrm{tr}(C^{-1}S) \right] $$여기서 \(S\)는 데이터의 sample covariance matrix이다. 즉, PPCA는 latent \(z\)를 직접 고정해 놓고 \(p(x \mid z)\)만 최대화하는 것이 아니라, 가능한 모든 latent \(z\)를 고려한 뒤 데이터 \(x\)가 전체적으로 얼마나 그럴듯하게 생성되는지를 나타내는 marginal likelihood를 최대화한다.
정리하면, 설명용으로는 \(p(x \mid z)\)의 log를 보면 reconstruction error와의 연결이 잘 드러난다. 하지만 PPCA의 실제 maximum likelihood 학습에서는 관측되지 않는 latent \(z\)를 적분한 marginal likelihood \(p(x)\)를 최대화한다. PPCA가 중요한 이유는 선형-Gaussian 구조 덕분에 이 적분과 posterior가 모두 닫힌 형태로 계산되며, 그 결과 PCA의 주성분 해를 확률적 생성모델의 관점에서 해석할 수 있기 때문이다.
여기서 PPCA의 선형-Gaussian 구조에서는 최종적으로 명시적인 maximum likelihood 해는 아래와 같다. 해 자체가 중요하지는 않지만 명시적인 해가 존재한다는 것은 중요하며, 데이터가 많은경우 아래의 식으로 해를 계산하기보다 EM알고리즘을 적용하는 것이 더 빠르다. 데이터 공분산 행렬의 상위 \(q\)개 고유벡터를 \(U_q\), 이에 대응되는 고유값 대각행렬을 \(\Lambda_q\)라고 하면, PPCA의 생성행렬 \(W\)에 대한 ML 해는 다음과 같이 주어진다.
$$ W_{ML} = U_q(\Lambda_q-\sigma^2 I)^{1/2}R $$여기서 \(R\)은 임의의 orthogonal rotation matrix이다. 또한 noise variance \(\sigma^2\)도 버려진 고유값들의 평균으로 계산된다.
$$ \sigma^2_{ML} = \frac{1}{D-q} \sum_{j=q+1}^{D}\lambda_j $$즉, PPCA는 decoder에 해당하는 \(W\)의 해를 공분산 행렬의 고유분해를 통해 명시적으로 얻을 수 있다. 또한 encoder에 해당하는 posterior \(p(z \mid x)\) 역시 닫힌 형태로 계산된다. \(M = W^\top W + \sigma^2 I\)라고 하면 posterior는 다음과 같다.
$$ p(z \mid x) = \mathcal{N} \left( M^{-1}W^\top(x-\mu), \sigma^2 M^{-1} \right) $$따라서 PPCA에서는 decoder의 ML 해와 encoder에 해당하는 posterior가 모두 명시적으로 존재한다. 다만 이 전체 유도는 현재 절의 핵심은 아니므로, 자세한 전개는 후속 부록에서 다룬다.
한편 위의 log likelihood 관점에서 EM 알고리즘도 자연스럽게 유도된다. 실제 데이터에서는 각 \(x_n\)에 대응되는 latent variable \(z_n\)이 관측되지 않기 때문에, 직접 complete-data log likelihood를 최대화할 수 없다. 따라서 EM은 먼저 E-step에서 현재 모수에 대한 posterior \(p(z_n \mid x_n)\)를 계산하고, M-step에서 그 posterior에 대한 기댓값을 이용해 \(W\), \(\mu\), \(\sigma^2\)를 갱신한다. PPCA의 경우 posterior가 Gaussian으로 닫힌 형태를 가지므로 E-step은 근사가 아니라 정확하게 수행된다. 즉, PPCA에서 EM은 posterior가 풀리지 않아서 사용하는 변분 근사법이 아니라, 명시적 해가 존재하는 같은 ML 문제를 반복적으로 푸는 계산적 대안이다. 특히 데이터 차원 \(D\)가 크고 잠재 차원 \(q\)가 작을 때는 \(D \times D\) 공분산 행렬의 고유분해를 직접 수행하는 것보다 EM 방식이 계산적으로 더 효율적일 수 있다.
3.3 Nonlinear AutoEncoder
시작 전에 전체 그림을 훑어보면, Nonlinear AutoEncoder는 Linear AutoEncoder의 선형 변환을 비선형 활성함수와 여러 층으로 확장한 모델이다. 구성요소(인코더·디코더·code layer)는 Linear AutoEncoder와 거의 같지만, 각 층에 sigmoid·tanh·ReLU 같은 비선형 함수가 들어가면서 모델의 성질이 근본적으로 달라진다. Linear AutoEncoder는 전체가 하나의 행렬곱으로 축약되어 PCA/SVD라는 닫힌 형태의 해를 가졌고, PPCA는 같은 구조를 선형-가우시안 확률모델로 옮겨 EM까지 사용할 수 있었다. 그러나 Nonlinear AutoEncoder는 비선형 합성 때문에 목적함수가 non-convex가 되고, 닫힌 형태의 해도 PPCA식 확률 해석도 더 이상 주어지지 않는다. 따라서 이 모델의 핵심 질문은 "해를 어떻게 직접 구하는가"가 아니라 "어떻게 학습시킬 것인가"이며, 이번 절의 중심도 그 학습 전략(단계적 사전학습 + 미세조정)에 있다.
이번 절은 수학적으로 엄격하게 전개하지 않는다. Nonlinear AutoEncoder의 초기 학습법은 Restricted Boltzmann Machine(RBM)에 기반하는데, RBM은 Boltzmann machine 계열에서 핵심적인 모델이지만(Hinton이 자신의 ML 연구 중 중요한 것으로 꼽았다) 그 내부 학습(contrastive divergence)은 그 자체로 큰 주제이고 현대 실무에서는 거의 쓰이지 않으므로, 여기서는 "계산을 다루기 쉽게 만들어 주는 building block" 정도로만 이해하고 깊이 다루지는 않는다.
3.3.1 Nonlinear AutoEncoder 예제
3.3.2 등장 배경
1988년 Bourlard & Kamp가 Linear AutoEncoder와 SVD/PCA의 관계를 보였고 [1], 이어 Baldi & Hornik이 그 손실 표면 분석(국소 최소 없음)을 제시하면서 [2] Linear AutoEncoder가 PCA와 동치임이 정리되었다. 이후 Linear AutoEncoder로 MNIST 같은 숫자나 Eigenface 같은 얼굴 이미지의 생성모델을 만들려는 시도가 여럿 등장했지만, 성능은 기대만큼 좋지 않았다. 이 흐름에서 입력·출력 신경망을 단일 층이 아니라 복수의 비선형 층으로 구성한 Nonlinear AutoEncoder가 등장해 더 높은 성능을 보이기 시작했다. 구성요소만 보면 Linear AutoEncoder와 큰 차이가 없는데도 성능이 좋아진 이유는, 비선형 활성함수와 복수 층 때문에 해를 찾는 방식 자체가 완전히 달라졌기 때문이다. 각 구성요소를 표로 비교해 보자.
3.3.3 구성요소 비교
| 구성 요소 | Linear AutoEncoder | Nonlinear AutoEncoder |
|---|---|---|
| recognition model (encoder, \(G\)) |
\(z = G(x) = W_e x\) | \(z = G_\phi(x)\) 여러 선형층과 비선형 activation의 합성 |
| generation model (decoder, \(H\)) |
\(\hat{x} = H(z) = W_d z\) | \(\hat{x} = H_\theta(z)\) 여러 선형층과 비선형 activation의 합성 |
| latent vector | \(z \in \mathbb{R}^q,\ q < D\) | \(z \in \mathbb{R}^q,\ q < D\) |
| information bottleneck | 있음 (차원 축소) | 있음 (차원 축소) |
| 재구성 비교 대상 | 입력 \(X\) ↔ 출력 \(\hat{X}\) | 입력 \(X\) ↔ 출력 \(\hat{X}\) |
| Layer 수 | 보통 단일 층으로 표현 가능 여러 선형층도 하나의 선형사상으로 축약됨 |
복수 층 |
| 활성 함수 | 항등 함수 (identity) | sigmoid, tanh, ReLU 등 비선형 단, code/output 층의 activation은 설정에 따라 달라질 수 있음 |
| 목적 함수 | \(\min_{W_e, W_d} \|X - W_d W_e X\|_F^2\) PCA/SVD와 연결됨 (단, 가중치에 대해 jointly convex는 아님) |
\(\min_{\phi,\theta} \|X - H_\theta(G_\phi(X))\|_F^2\) 비선형 합성으로 일반적으로 non-convex |
| 해를 찾는 방식 | 최적 저차원 부분공간을 PCA/SVD로 구함 신경망으로 학습하면 gradient descent도 가능 |
backpropagation 기반 반복 최적화 초기 연구에서는 RBM pretraining 후 fine-tuning |
표에서 보듯 구성요소 자체는 거의 동일하다. 차이는 "활성 함수", "목적 함수", "해를 찾는 방식"의 세 칸에 응축되어 있고, 이 세 칸이 사실상 Nonlinear AutoEncoder의 모든 어려움과 해법을 결정한다. 왜 그런지, 직접 해를 구할 수 없는 이유부터 따져 보자.
3.3.4 직접 해를 구할 수 없는 이유
Linear AutoEncoder의 각 노드에는 별다른 규칙이 없었다. 데이터가 들어오면 선형으로 그대로 다음 층에 전달했고, 그래서 여러 선형층을 쌓더라도 결국 다음처럼 하나의 행렬 \(P\)로 합쳐져 단일 선형사상과 다를 바가 없었다.
반면 Nonlinear AutoEncoder는 code layer(information bottleneck이 적용된 층)를 제외한 모든 층에 sigmoid 같은 비선형 활성함수 \(f\)를 적용한다(편의상 bias는 생략). 그러면 forward pass는 다음처럼 비선형 함수가 중첩된 형태가 된다.
여기서 \(f\)가 비선형이므로 이 합성은 더 이상 하나의 행렬로 축약되지 않는다. 그 결과 다음 네 가지 길이 모두 막힌다. (i) SVD처럼 닫힌 형태로 최적 부분공간을 뽑아낼 수 없다. (ii) 목적함수 \(\min_{\phi,\theta}\|X - H_\theta(G_\phi(X))\|_F^2\)는 일반적으로 non-convex여서 전역 최적해의 존재나 위치를 보장하기 어렵다. (iii) 입력만 보고 어떤 노드가 활성화될지 미리 알 수 없으므로, Linear AutoEncoder에서 가능했던 "입력-출력 오차로부터 \(W_e, W_d\)를 직접 계산"하는 방식도 쓸 수 없다. (iv) 이 모델은 PPCA처럼 선형-가우시안 확률모델로 해석되지 않으므로 EM 같은 확률적 테크닉도 적용할 수 없다. 결국 한 번에 해를 구하는 길이 모두 막혀 있고, 그래서 학습을 단계로 나누는 전략이 필요해진다.
3.3.5 Deep AutoEncoder의 구조
Deep autoencoder는 encoder와 decoder를 각각 여러 층으로 쌓고, 중심에 작은 code layer를 둔 구조이다. Hinton과 Salakhutdinov(2006) [8]의 MNIST 실험에서 쓰인 구조는 다음과 같다.
입력 784차원(28×28 이미지)이 여러 비선형 층을 거쳐 30차원 code로 압축되고, 대칭 구조의 decoder가 다시 784차원으로 복원한다. 각 층 사이에 비선형 activation이 들어가므로 전체 함수 \(H_\theta \circ G_\phi\)는 비선형이며, 3.3.4의 선형 분석(닫힌 해)은 적용되지 않는다.
3.3.6 단계적 학습: pretraining과 fine-tuning
직접 해가 막혀 있으니, 초기 deep autoencoder 연구(Hinton & Salakhutdinov, 2006)는 학습을 두 단계로 나눴다. 먼저 각 층을 따로따로 비지도로 사전학습하여 좋은 초기값을 만들고, 그다음 그 초기값에서 전체 네트워크를 backpropagation으로 미세조정하는 방식이다.
1단계 — 층별 사전학습(greedy layer-wise pretraining). 가장 아래 층(입력 → 첫 은닉층)을 하나의 RBM으로 보고, 입력 데이터의 분포를 비지도로 학습해 가중치 \(W_1\)을 얻는다. 그다음 \(W_1\)을 고정하고 첫 은닉층의 활성값을 계산한 뒤, 그 활성값을 입력으로 삼는 두 번째 RBM을 학습해 \(W_2\)를 얻는다. 이렇게 code layer까지 한 층씩 탐욕적으로(greedy) 쌓아 올린다. 각 RBM은 바로 아래 층의 표현을 잘 재현하도록 학습되므로, 위로 갈수록 점점 더 추상적인 특징이 누적된다. (RBM 대신 각 층을 얕은 autoencoder로 사전학습하는 변형을 stacked autoencoder라고 부른다.)
2단계 — unroll 후 미세조정. 사전학습으로 얻은 인코더 가중치들을 펼치고(unroll), 그 전치(혹은 대칭 구조)를 디코더로 두어 전체 deep autoencoder를 구성한다. 이제 무작위 초기값이 아니라 이미 의미 있는 가중치에서 출발하므로, 전체 네트워크를 backpropagation으로 reconstruction error \(\min_{\phi,\theta}\|X - H_\theta(G_\phi(X))\|_F^2\)를 최소화하도록 미세조정한다.
이 두 단계가 왜 필요한지가 핵심이다. 원논문의 표현으로도 backpropagation에 의한 fine-tuning은 "초기 weight가 좋은 해 근처에 있을 때만" 잘 작동한다. 무작위 초기화에서 곧장 깊은 네트워크를 학습하면 아래층으로 갈수록 gradient가 사라지는 vanishing gradient 문제와 나쁜 local minimum에 빠지기 쉬웠다. 층별 비지도 사전학습은 가중치를 미리 좋은 영역(basin)에 놓아두어, 이후의 미세조정이 안정적으로 수렴하도록 돕는다. 즉 "한 번에 풀 수 없으면, 나눠서 좋은 출발점을 만든 뒤 전체를 다듬는다"가 기본 아이디어다.
다만 RBM 내부 학습(contrastive divergence)은 별도의 큰 주제이므로 여기서는 다루지 않는다. 또한 이후 ReLU activation, Xavier/He 초기화, batch/layer normalization, Adam 같은 최적화 기법이 발전하면서 무작위 초기값에서도 깊은 autoencoder를 backpropagation만으로 안정적으로 학습할 수 있게 되었다. 그래서 RBM 사전학습은 현재 거의 쓰이지 않고 주로 역사적·이론적 의의로 남아 있다.
3.3.7 성능: PCA를 넘어서
Hinton과 Salakhutdinov(2006) [8]는 deep autoencoder가 PCA보다 훨씬 나은 저차원 code를 학습한다는 것을 여러 데이터에서 보였다. 가장 잘 알려진 결과는 MNIST를 2차원 code로 압축했을 때이다. PCA로 2차원 projection한 경우 서로 다른 숫자 클래스가 뭉개져 섞이는 반면, deep autoencoder의 2차원 code는 숫자 클래스별로 뚜렷이 분리된 군집을 형성한다.
이 차이의 핵심은 표현력이다. Linear AutoEncoder는 데이터를 선형 부분공간으로 projection하는 데 그치지만, 비선형 AutoEncoder는 데이터가 놓인 휘어진 구조를 따라갈 수 있다. 데이터가 선형 부분공간이 아니라 곡면 위에 분포한다면, 그 곡면을 펴서 저차원으로 옮기는 일은 선형 변환으로는 불가능하고 비선형 함수만이 할 수 있다. 이 연구는 비선형 deep AutoEncoder가 PCA를 실증적으로 능가한다는 사실을 처음으로 설득력 있게 보였으며, deep learning 시대의 분수령으로 평가된다.
그러나 표현력이 커졌다고 해서 AutoEncoder가 generative model이 되는 것은 아니다. AutoEncoder는 정의상 입력을 하나의 출력으로 결정론적으로 복원하도록 설계되어 있어, 아무리 잘 학습해도 분포로부터 새로운 데이터를 생성하는 모델은 아니다. 바로 이 한계가 다음 장에서 VAE로 넘어가는 출발점이 된다.
3.3.8 보충: 왜 비선형이 필요한가 — 세 가지 질문
Nonlinear AutoEncoder에서 정말 이해해야 할 것은 구성요소가 어떻게 바뀌었는지, 그리고 Linear AutoEncoder가 잘 작동하던 가정이 언제 깨지는지이다. 앞선 Linear AutoEncoder의 가정으로부터 다음 세 질문을 구성한다.
- Linear AutoEncoder는 선형 영역에서 PCA와 동치이고 좋은 성능을 낸다고 하자. 그런데 데이터셋 A는 내재 차원이 분명히 낮은데도(저차원 구조가 있는데도) PCA/Linear AutoEncoder로는 차원 축소가 잘 되지 않고, 게다가 각 차원이 서로 무상관(uncorrelated)이다. 원인은 무엇일까?
- 1번의 진단에 따라 어떤 방법을 써야 제대로 성능을 낼 수 있을까?
- 2번의 비선형 인코더도 여전히 각 code 좌표를 좌표 간 연결 없이 만든다. 만약 잠재 표현 내부의 좌표들이 서로 의존하는 구조까지 모델링해야 한다면, 즉 같은 층 안의 유닛들이 서로 영향을 주어야 한다면, 2번 방법이 그대로 적용될까?
- PCA/Linear AutoEncoder는 데이터의 2차(공분산) 구조만 본다. 차원들이 무상관이면 공분산에는 활용할 신호가 거의 없다. 그러나 무상관은 독립이 아니다 — 변수들은 무상관이면서도 비선형 관계로 강하게 종속될 수 있다. 데이터가 휜 다양체(manifold) 위에 놓이면 내재 차원은 낮지만 그 저차원 구조가 비선형 종속의 형태로만 존재하므로 공분산에는 드러나지 않는다. 예컨대 \(t \sim \mathrm{Unif}[0,2\pi)\)에서 \(x = (\cos t, \sin t)\)는 두 좌표가 무상관이고 공분산이 \(\tfrac{1}{2}I\)로 등방이라 PCA가 선호할 방향이 없지만, 내재 차원은 \(t\) 하나뿐인 1차원이다. 즉 closed-form PCA 해는 유클리드 기준의 선형 부분공간 복원에 한해 최적일 뿐, 휜 다양체의 내재 저차원 구조는 잡지 못한다.
- 인코더·디코더를 비선형으로 만들어야 한다. 두 갈래가 있다. (a) 다양체의 기하를 다루는 manifold learning — 예: Isomap은 곡률을 직접 계산하는 것이 아니라, 최근접이웃 그래프 위의 최단경로로 측지거리(geodesic distance)를 근사한 뒤 저차원에 임베딩한다. (b) 비선형 활성함수를 쌓아 휜 구조의 펴짐을 근사하는 nonlinear AutoEncoder — 기하를 명시적으로 계산하지 않고도 복잡한 변환을 학습한다. 이 절이 따르는 길이 (b)다.
- 그대로는 어렵다. (a)·(b)의 feed-forward 인코더는 결정론적 code를 만들 뿐, code 좌표들 사이의 의존을 모델링하지 않는다. 좌표들이 서로 영향을 주는 구조, 즉 같은 층 안에서 유닛이 결합하는 모델이 필요해지면 energy-based model인 Boltzmann machine 영역으로 넘어간다. 그런데 모든 유닛이 연결된 완전 Boltzmann machine은 쌍별 상호작용이 \(O(n^2)\)로 늘어 학습이 어렵다. 그래서 같은 층 내 연결을 제거(restrict)하여 층 안에서는 조건부 독립이 되도록 만든 것이 바로 3.3.6의 building block인 RBM이다. (잠재 표현을 분포로 모델링한다는 이 발상은 이후 확률적 잠재변수 모델과 VAE로 이어진다.)
3.3.9 정리
정리하면, Nonlinear AutoEncoder는 비선형 함수의 합성 때문에 닫힌 형태의 해도 PPCA식 확률 해석도 주어지지 않으므로 한 번에 해를 구할 수 없다. 대신 층별 비지도 사전학습으로 좋은 초기값을 만들고 backpropagation으로 미세조정하는 단계적 학습을 통해 깊은 비선형 표현을 얻으며, 그 결과 PCA를 넘어서는 저차원 표현을 학습한다. 다만 표현력이 커져도 결정론적 복원이라는 정의 때문에 generative model은 아니다. "한 번에 못 풀면 나눠서 좋은 초기값을 만들고 다듬는다"는 사고와 "잠재 표현을 분포로 모델링한다"는 두 갈래가, 다음 장 확률적 생성모델과 VAE의 밑바탕이 된다.
3.4 Helmholtz Machine
앞 절의 PPCA는 PCA를 확률적 잠재변수 모델로 재해석한 방법이었다. Linear AutoEncoder가 제곱 재구성 오차를 최소화할 때 PCA의 주성분 부분공간과 연결되듯, PPCA는 latent에 Gaussian prior를 두고 decoder를 선형-Gaussian 조건부분포로 명시함으로써 같은 선형 잠재공간을 생성모델의 관점에서 설명한다. 그러나 AutoEncoder 분야에서 정작 잠재벡터와 신경망을 직접적으로 연결한 연구는 조금 통계학과는 거리가 있는 통계물리학과 정보이론쪽에서 진행이 되었다.
Helmholtz Machine은 latent vector를 명시적으로 학습시킬수 있는 구조를 도입하기 위해 기존의 encoder decoder를 하나의 곱해진 행렬로 보는 방식을 버리고 각각을 recognition model과 generative model라고 새롭게 명명한 뒤 그 사이에 있는 것이 latent code로 보았다(vector). 그리고 잠재 벡터의 평균이나 분포는 알려져 있지 않기 때문에 이를 log-likelihood식을 세우고, 이것을 볼츠만 분포에 비유하여 온도가 1인 자유에너지 식과 형태가 같음을 가정하여 수학적으로 동형인 문제임을 가정했다. 이것으로 헬름홀츠 자유 에너지 공식을 사용할수 있게되는데 일반적으로 에너지는 서로 멀어졌을때 엔트로피가 낮아짐으로 latent vector가 어떤 평균을 중심으로 clusterd된 분포가 생성되고 에너지가 낮아지면, 이것이 잠재벡터가 올바르게 구별된다는 개념을 도입하였다.
Helmholtz Machine은 latent vector를 명시적으로 학습시킬수 있는 구조를 도입하기 위해 기존의 encoder decoder를 하나의 곱해진 행렬로 보는 방식을 버리고 각각을 recognition model과 generative model라고 새롭게 명명한 뒤 그 사이에 있는 것이 latent code로 보았다(vector). 그리고 explanation $\alpha$의 평균이나 분포는 알려져 있지 않기 때문에 이를 log-likelihood식을 세우고, 이것을 볼츠만 분포에 비유하여 온도가 1인 자유에너지 식과 형태가 같음을 가정하여 수학적으로 동형인 문제임을 가정했다. 이것으로 헬름홀츠 자유 에너지 공식을 사용할수 있게되는데 일반적으로 에너지는 서로 멀어졌을때 엔트로피가 낮아짐으로 explanation $\alpha$가 어떤 평균을 중심으로 clusterd된 분포가 생성되고 에너지가 낮아지면, 이것이 잠재 표현이 올바르게 구별된다는 개념을 도입하였다.
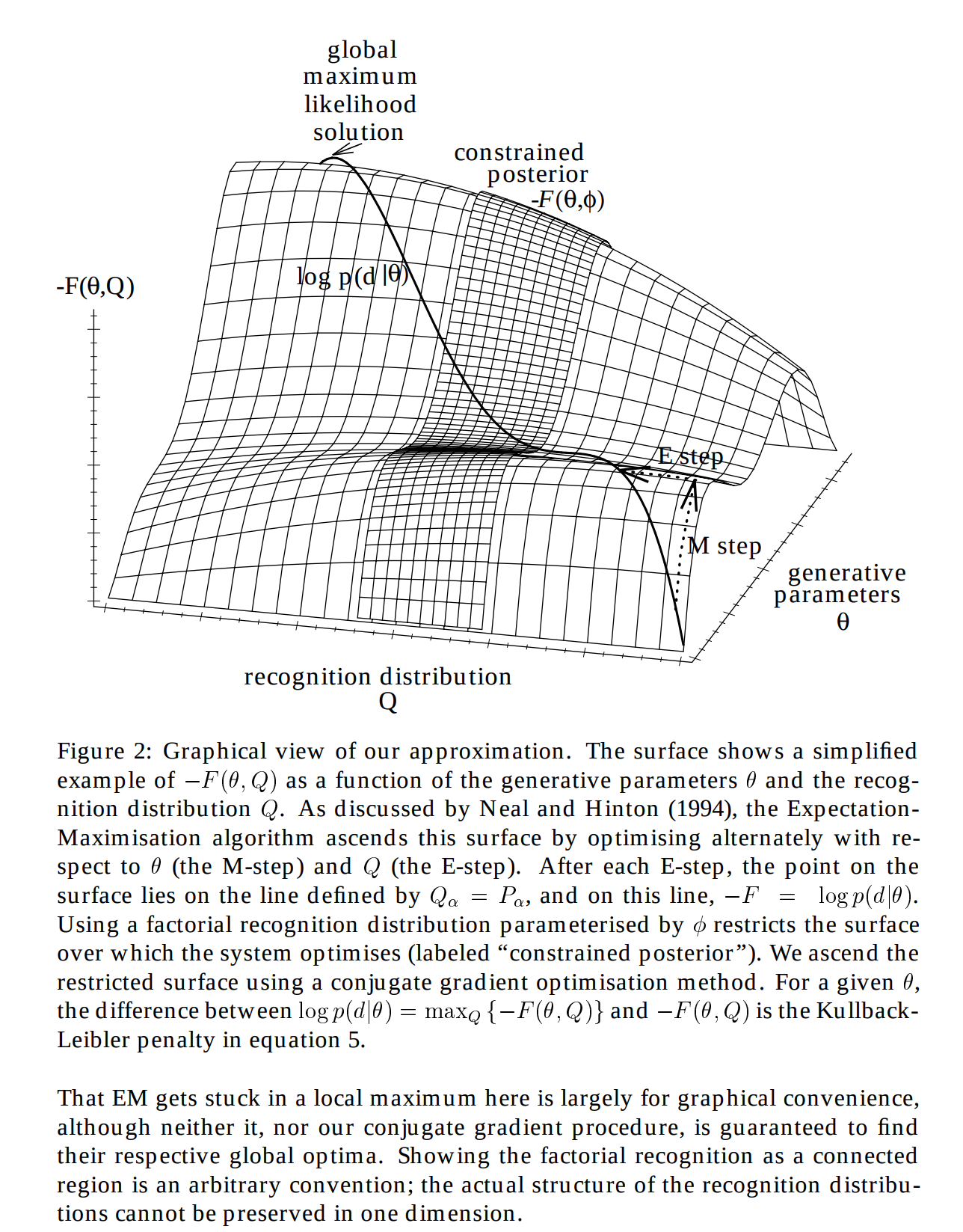
3.4.1 Variational free energy와 하한
$p(d|\theta)$는 생성 모델(generative model)이 파라미터 $\theta$로 표현될때, 데이터 d를 만들어낼 확률이다. 따라서 이 생성에 관여하는 각 explanation, 즉 latent vector, $\alpha$의 에너지를 $E_\alpha = -\log p(\alpha \mid \theta)\,p(d \mid \alpha, \theta)$로 정의하면 (식 2.2), 진짜 posterior $P_\alpha$는 Boltzmann 분포로 주어지며 이때 자유에너지는 정확히 $-\log p(d \mid \theta)$와 같다 (식 2.4). 그러나 $P_\alpha$는 explanation 수가 지수적으로 많아 다룰 수 없으므로, $P_\alpha$ 자리에 우리가 직접 다룰 수 있는 recognition 분포 $Q_\alpha$를 대신 끼워 넣는다.
1단계. $\log p(d \mid \theta)$를 explanation에 대한 합으로 쓰고, 분자·분모에 $Q_\alpha$를 곱한 뒤 $P_\alpha = p(\alpha, d \mid \theta) / p(d \mid \theta)$ 관계를 이용한다.
$$\log p(d \mid \theta) = \log \sum_\alpha p(\alpha, d \mid \theta) = \sum_\alpha Q_\alpha \log \frac{p(\alpha, d \mid \theta)}{Q_\alpha} + \sum_\alpha Q_\alpha \log \frac{Q_\alpha}{P_\alpha}$$이는 부등식이 아니라 등식이다 ($P_\alpha$가 정확한 posterior이기 때문). 첫 항을 $E_\alpha = -\log p(\alpha, d \mid \theta)$로 정리하면 원논문 식 2.5가 된다.
$$\log p(d \mid \theta) = -\sum_\alpha Q_\alpha E_\alpha - \sum_\alpha Q_\alpha \log Q_\alpha + \sum_\alpha Q_\alpha \log \frac{Q_\alpha}{P_\alpha}$$2단계. 마지막 항 $\sum_\alpha Q_\alpha \log(Q_\alpha / P_\alpha)$는 $Q$와 진짜 posterior $P$ 사이의 Kullback–Leibler divergence로, 항상 $0$ 이상이고 $Q_\alpha = P_\alpha$일 때에만 $0$이 된다. 따라서 첫 두 항만 떼어내면 $\log p(d \mid \theta)$의 하한이 된다.
$$\log p(d \mid \theta) \;\geq\; -\sum_\alpha Q_\alpha E_\alpha - \sum_\alpha Q_\alpha \log Q_\alpha$$3단계. 부호를 정리하여 우변을 $-\mathcal{F}(d; \theta, Q)$로 명명한다 (식 2.6). 곧 $\mathcal{F}$는 기대 에너지에서 entropy를 뺀 양, 즉 $Q$ 분포에 기반한 자유에너지이다.
$$\mathcal{F}(d; \theta, Q) = \underbrace{\sum_\alpha Q_\alpha E_\alpha}_{\langle E \rangle_Q,\;\text{기대 에너지}} \;-\; \underbrace{\Big(-\sum_\alpha Q_\alpha \log Q_\alpha\Big)}_{H[Q],\;\text{recognition entropy}}$$그러면 식 2.5는 다음과 같이 깔끔히 정리된다.
$$\log p(d \mid \theta) = -\mathcal{F}(d; \theta, Q) + \sum_\alpha Q_\alpha \log \frac{Q_\alpha}{P_\alpha}$$이 가정을 통해, 직접 다룰 수 없는 $\log p(d \mid \theta)$ 대신, 다룰 수 있는 하한 $-\mathcal{F}$를 최대화하면 된다. $\theta$에 대해 $-\mathcal{F}$를 올리면 generative model이 데이터에 맞춰지고, $\phi$에 대해 ($Q$가 $\phi$로 파라미터화되어 있으므로) 올리면 KL 항이 줄어 하한이 실제 likelihood에 가까워진다 (bound가 tight해진다). 이 하한 $-\mathcal{F}$가 바로 ELBO (evidence lower bound)와 같은 의미이다. 아직까지도 ELBO를 자유에너지 최적화라고 하는 까닭은 헬름홀츠 머신 모델의 논문이 사실 ELBO보다 출판되었기 때문이다.
하한을 최대화한다는 개념을 자유에너지와 정보이론을 결합하여 수학적으로 모델링을 한다. VAE 원논문 [13]이 직접 디딘 선행연구가 PPCA가 아니라 Helmholtz Machine 계열인 이유가 여기에 있다 (Dayan, Hinton, Neal & Zemel [29]).
3.4.2 두 개의 결합된 네트워크
Helmholtz Machine의 출발점은 지각(perception)에 대한 하나의 관점이다. Helmholtz는 뇌가 감각 입력을 받아 그 입력을한 만들어 낸 숨은 원인을 추론한다고 보았다. 곧 지각이란 일종의 "무의식적 추론"이며, 이를 기계로 옮기면 데이터 $x$를 관측하고 그 배후의 latent 원인 $z$를 추정하는 문제가 된다.
이 관점을 모델로 만들면 두 개의 네트워크가 필요하다. 하나는 latent 원인에서 데이터를 만들어 내는 generative model (top-down)이고, 다른 하나는 데이터로부터 그 원인을 거꾸로 추론하는 recognition model (bottom-up)이다.
원래의 Helmholtz Machine에서 latent는 하나의 벡터가 아니라 여러 층으로 쌓인 $z = (z^1, \ldots, z^L)$이며, generative model은 위층에서 아래층으로, recognition model은 아래층에서 위층으로 한 층씩 조건부 분포를 곱해 나간다.
각 층의 unit은 binary stochastic이고, 한 층의 조건부 분포는 이웃 층이 주어졌을 때 unit들이 서로 독립이라고 가정한다. 곧 각 unit이 켜질 확률을 sigmoid로 주는 factorial sigmoid 조건부이다.
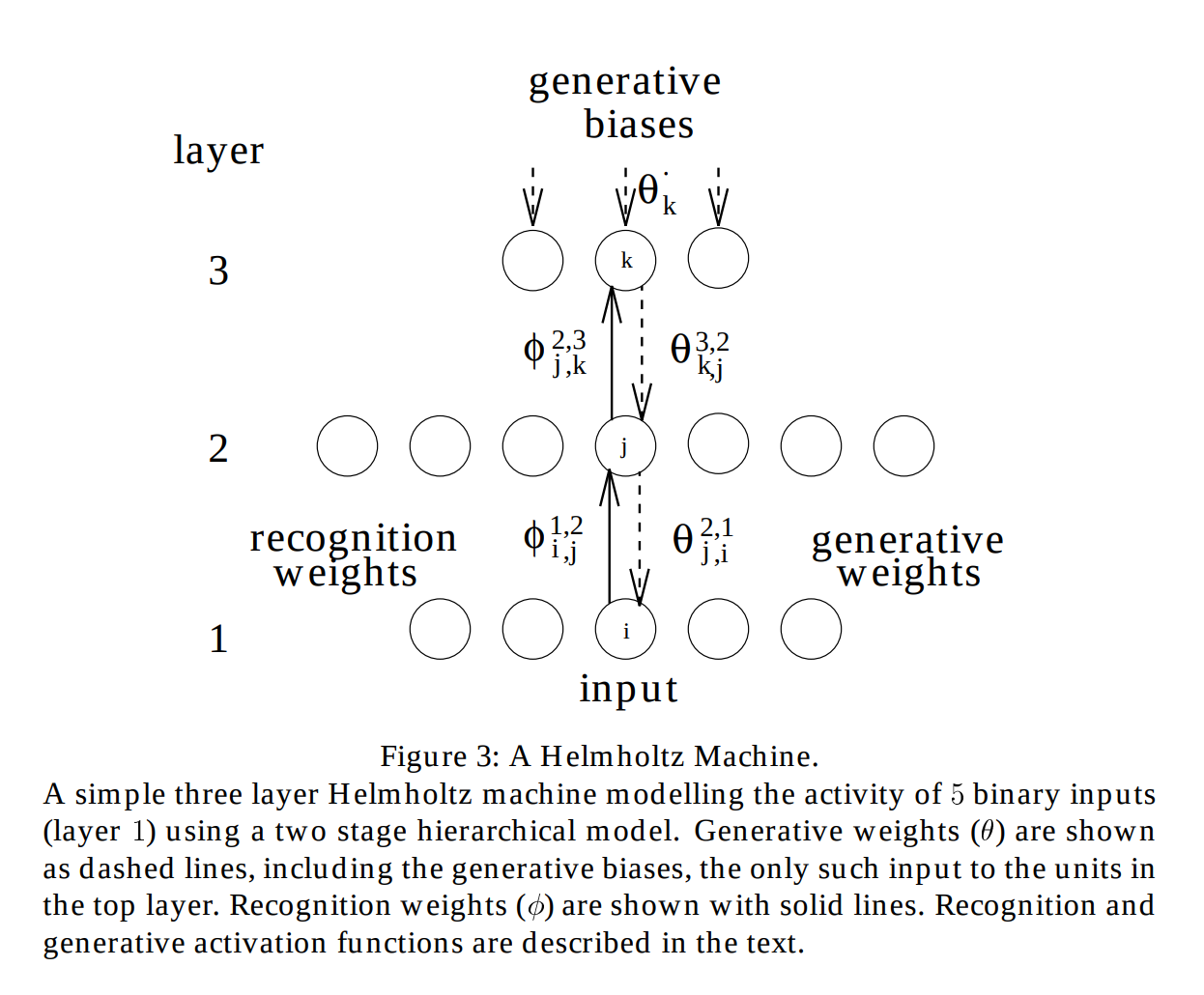
이는 2.2.2에서 본 Bernoulli 모델링 ($\hat{\pi} = \operatorname{sigm}(\cdot)$)을 층마다 반복한 구조와 정확히 같다. 그리고 두 네트워크의 역할은 우리가 2장 내내 다뤄 온 것과 대응된다. recognition model $q_\phi(z \mid x)$는 데이터를 latent로 보내는 encoder에, generative model $p_\theta(x \mid z)$는 latent에서 데이터를 복원하는 decoder에 해당한다. VAE가 물려받는 것이 바로 이 짝 구조이다.
2.5.2 다루기 힘든 log-likelihood
generative model을 데이터에 맞추는 표준적인 방법은 maximum likelihood, 곧 $\log p_\theta(x)$의 최대화이다. 그런데 latent variable 모델에서 이 양은 모든 가능한 latent 값에 대한 합으로 주어진다.
Helmholtz Machine의 원논문은 각 latent 값 $z$를 데이터 $x$에 대한 하나의 explanation (설명) 이라 부른다. 문제는 하나의 패턴 $x$를 만들어 낼 수 있는 explanation이 일반적으로 지수적으로 많다는 점이다. $L$개 층에 각각 $h$개의 binary unit이 있으면 가능한 $z$는 $2^{hL}$개에 이른다. 이 합을 직접 계산하는 것도, posterior $p_\theta(z \mid x)$를 구하는 것도 현실적으로 불가능하며, 그렇기 때문에 EM처럼 posterior를 정확히 요구하는 표준 maximum likelihood 기법도 쓸 수 없다.
따라서 직접 다룰 수 없는 $\log p_\theta(x)$ 대신, 다룰 수 있으면서 그것을 대신할 수 있는 다른 양이 필요하다. 그 양이 다음 절의 variational free energy이다.
2.5.4 Factorial 가정과 explaining-away
2.5.3의 하한은 $q_\phi$가 무엇이든 성립하지만, 하한이 실제 likelihood와 얼마나 가까운지는 $q_\phi$가 진짜 posterior $p_\theta(z \mid x)$를 얼마나 잘 흉내 내는지에 달려 있다. 그런데 Helmholtz Machine의 recognition model은 계산 가능성을 위해 각 층의 unit들이 서로 독립이라고 가정한다 — 곧 factorial이다.
문제는 진짜 posterior가 factorial이 아니라는 데 있다. 두 latent 원인 $z_1, z_2$가 모두 같은 데이터 $x$를 만들어 낼 수 있다고 하자. $x$를 관측하면 두 원인은 posterior에서 서로 의존하게 된다. 한 원인이 켜져 있다는 사실이 $x$를 이미 설명해 버리면, 다른 원인이 켜져 있을 필요가 줄어들기 때문이다. 이를 explaining-away (설명 떠넘기기) 라 부른다. 그 결과 prior $p_\theta(z)$가 factorial이더라도 posterior $p_\theta(z \mid x) \propto p_\theta(z)\, p_\theta(x \mid z)$는 latent들 사이에 상관을 가진다.
따라서 factorial한 $q_\phi$는 — 파라미터를 아무리 많이 줘도 — 상관을 가진 posterior에 결코 도달할 수 없다. KL 항은 $0$으로 내려가지 못하고, 하한과 실제 likelihood 사이에는 메울 수 없는 간격이 남는다.
이 간격은 최적화를 더 오래 돌려서 줄일 수 있는 것이 아니라, $q_\phi$의 표현력 자체에서 오는 구조적 한계라는 점이 핵심이다. 덧붙이면, VAE도 보통 diagonal Gaussian이라는 factorial한 $q_\phi$를 쓰므로 같은 종류의 간격을 그대로 물려받는다. 더 표현력 있는 recognition model로 이 간격을 줄이는 것은 이후 연구의 한 갈래가 된다.
2.5.5 Wake-sleep 알고리즘
그렇다면 $\theta$와 $\phi$를 실제로 어떻게 학습하는가? Helmholtz Machine의 학습 알고리즘이 wake-sleep이다 (Hinton, Dayan, Frey & Neal [30]). 이름 그대로 학습은 깨어 있는 단계와 잠자는 단계, 두 phase를 번갈아 진행한다.
| Phase | wake · 데이터로 구동 | sleep · 환상으로 구동 |
|---|---|---|
| 입력 | 실제 데이터 $x$를 입력에 고정(clamp) | 입력 없음. generative model을 top-down으로 돌려 가짜 $(x, z)$를 "꿈꾼다" |
| 샘플링 | recognition model을 한 번 bottom-up으로 돌려 $z \sim q_\phi(z \mid x)$ | prior $p_\theta(z^L)$에서 시작해 아래로 내려가며 $(x, z) \sim p_\theta$ |
| 갱신 | $\theta$를 갱신해 $\log p_\theta(x, z)$를 높인다 | $\phi$를 갱신해 $\log q_\phi(z \mid x)$를 높인다 |
sleep phase의 발상이 특히 우아하다. recognition model은 실제 데이터에 대해서는 정답 latent를 결코 알 수 없지만, generative model이 스스로 "꿈꾼" $(x, z)$ 쌍에서는 $z$가 무엇이었는지 이미 알고 있다. 그 꿈을 (입력, 정답) 쌍처럼 써서 $q_\phi$가 현재의 generative model을 거꾸로 뒤집도록 가르치는 것이다. 두 갱신 모두 sigmoid belief net에서 각 연결에 대해 "실제 활성 $-$ 예측 활성" 형태의 국소 delta rule로 떨어지며, 오차를 충층이 역전파할 필요가 없다. 이 생물학적 그럴듯함이 원논문의 주요 동기 중 하나였다.
2.5.6 Wake-sleep의 한계와 VAE로의 다리
wake-sleep은 우아하지만 한 가지 결정적인 약점이 있다. 두 phase가 함께 최적화하는 단일 목적 함수가 존재하지 않는다는 것이다.
wake phase는 문제가 없다. entropy $H[q_\phi]$가 $\theta$와 무관하므로, wake phase는 $\mathcal{F}$를 $\theta$에 대해 줄이는 정확한 갱신이다. 문제는 sleep phase에 있다. sleep phase가 실제로 최소화하는 것은 $\mathcal{F}$ 안에 들어 있는 KL 항이 아니라, 방향이 뒤집힌 KL을 꿈꾼 데이터 위에서 평균 낸 양이다.
두 가지 어긋남이 겹친다. 첫째, 방향의 어긋남 — $\mathcal{F}$는 $D_{\mathrm{KL}}(q_\phi \,\|\, p_\theta)$를 담고 있는데 sleep phase는 그 반대 방향 $D_{\mathrm{KL}}(p_\theta \,\|\, q_\phi)$를 줄인다. 두 KL은 최소점이 다르다. 둘째, 분포의 어긋남 — $q_\phi$는 실제 데이터가 아니라 generative model이 꿈꾼 $x$ 위에서 학습되는데, 모델이 아직 형편없을 때 그 꿈은 실제 데이터와 동떨어져 있다. 그 결과 wake-sleep은 하나의 함수를 단조롭게 내려가는 알고리즘이 아니라, 수렴이 보장되지 않고 진동할 수도 있는 휴리스틱한 번갈아-갱신 방식이 된다.
바로 이 빈자리를 VAE가 채운다. VAE는 wake-sleep의 두 어긋난 갱신을, $\theta$와 $\phi$에 대해 동시에 최적화되는 단일 목적 함수 — 곧 ELBO ($-\mathcal{F}$) — 로 통합한다. 이를 가능하게 하는 핵심 장치가 reparameterization trick으로, 3장에서 다룬다. 한편 Neal과 Hinton [27]이 보였듯 EM 자체도 같은 free energy $\mathcal{F}(\theta, Q)$에 대한 coordinate descent로 볼 수 있으며, 이 관점에서 Helmholtz Machine은 그 E-step을 neural network로 amortize한 변분 EM에 해당한다. 정리하면, VAE는 Helmholtz Machine에서 recognition model과 generative model의 짝 구조를 물려받고, 흩어져 있던 그 학습을 단일 ELBO의 최적화로 다시 세운 모델이다.
3.5 AutoEncoder의 한계: generative model로서의 실패
지금까지 다룬 AutoEncoder는 주어진 입력을 압축하고 복원하는 데 사용된다. 그러나 머신러닝의 또 다른 큰 관심사는 새로운 데이터를 만들어 내는 모델, 곧 generative model이다. 학습 데이터에 없던 새로운 고양이 사진, 새로운 손글씨, 새로운 문장을 생성할 수 있는 모델을 가리킨다.
Generative model은 데이터 분포 $p_{\text{data}}(x)$를 근사하는 모델 $p_\theta(x)$를 학습하고, 이 모델로부터 새로운 sample $\tilde{x} \sim p_\theta(x)$를 생성할 수 있는 모델이다. 학습 데이터에 정확히 일치하지 않으면서도 데이터 분포의 성질을 따르는 새로운 example을 만들어 낸다.
AutoEncoder의 decoder $g_\theta : \mathbb{R}^d \to \mathbb{R}^D$가 새로운 데이터 생성에 직접 활용될 수 있는지 묻는 것이 자연스럽다. MNIST로 잘 학습된 AutoEncoder를 가정하고, decoder에 임의의 $z \sim \mathcal{N}(0, I)$를 넣어 보자. 결과는 거의 항상 의미를 알 수 없는 노이즈에 가까운 출력이다. 학습 데이터에 대해서는 잘 복원하는 decoder인데도 무작위 $z$에 대해서는 의미 있는 손글씨가 나오지 않는다.
이 실패의 원인은 latent space의 구조에 있다. 학습된 AutoEncoder의 latent space에는 두 종류의 영역이 존재한다. 학습 데이터의 encoded 표현 $z_i = f_\phi(x_i)$에 해당하는 점들의 근처와, 그 외의 영역이다. 첫 영역에서 decoder는 잘 작동하지만, 둘째 영역에서는 decoder가 무엇을 출력할지 보장되지 않는다. Standard Gaussian에서 뽑은 임의의 $z$는 거의 확실히 둘째 영역에 떨어지는데, 학습된 latent vector $z_i$들이 어떤 데이터 의존적 분포를 따라 분포할 뿐 $\mathcal{N}(0, I)$와 일치할 보장이 없기 때문이다. 2.3의 linear AE 분석에서 이미 본 사실이다. 손실은 latent vector들의 위치를 결정할 뿐 latent covariance가 $\Lambda_d$인지 $I$인지 그 사이의 어떤 형태인지를 결정하지 않으며, 따라서 학습된 latent vector들이 어떤 특정 분포를 따른다고 가정할 근본적 이유가 없다.
AutoEncoder가 generative model로 작동하려면 latent space가 다음 세 조건을 만족해야 한다.
- Continuity: Latent space의 가까운 점들이 decoder를 통과한 후에도 입력 공간의 가까운 점으로 mapping되어야 한다. 곧 decoder가 연속함수처럼 작동해야 한다.
- Completeness: 학습된 latent 영역의 임의의 점, 그리고 그 영역 안의 점들 사이의 보간 점에 대해서도 의미 있는 출력이 보장되어야 한다.
- Samplability: Latent 영역에서 새로운 점을 뽑을 수 있는 명확한 sampling 절차가 존재해야 한다. 이를 위해서는 latent 분포가 알려진 형태여야 한다.
표준 AutoEncoder는 세 조건 중 어느 것도 만족하지 않는다.
이 세 조건을 한꺼번에 해결하는 발상은 다음과 같다. Encoder가 입력을 latent space의 한 점이 아니라 분포로 mapping하도록 정의한다. 그러면 학습 과정에서 매번 그 분포로부터 다른 점을 뽑아 decoder에 입력하게 되고, 결과적으로 decoder는 한 점뿐만 아니라 그 주변 영역 전체에서 학습 신호를 받는다. Latent space가 점이 아니라 영역으로 채워지는 셈이다. 이것이 Variational AutoEncoder의 출발 아이디어이다.
Variational AutoEncoder
AutoEncoder의 세 한계를 확률 모델로 재정의하여 해결한다. 본 장은 모델 정의, 손실함수 (ELBO) 유도, 학습 알고리즘 순으로 전개한다.
2.6에서 정리한 AutoEncoder의 한계는 세 가지였다. 이를 다시 짚어 둔다.
- Latent 공간에 명시적 prior가 없다. 손실은 latent vector의 위치만 결정할 뿐 분포 형태에는 제약을 가하지 않는다 (2.3의 invertible $A$ 모호성). 학습 후 latent vector들이 어떤 분포로 흩어졌는지 알 수 없으며, 새 데이터 생성 시 어디서 $z$를 뽑아야 할지에 대한 답이 없다.
- Encoder가 한 점에 매핑한다. 같은 $x$에 대해 항상 같은 $z$가 나오므로 학습 신호가 학습된 점 근처에만 도달하고 그 외 영역으로 퍼지지 않는다. Decoder는 함수로서 모든 $z$에 대해 출력을 내지만, 학습 신호가 닿지 않은 영역에서는 그 출력이 데이터다운 결과라는 보장이 없다.
- 확률 모델이 아니다. Encoder와 decoder 모두 deterministic 함수이며 손실은 외부에서 $\|x - \hat{x}\|^2$로 정의된다. 데이터의 likelihood라는 표준 학습 원리를 사용하지 못한다.
VAE는 이 세 한계를 정확히 다음 네 가지로 업데이트한다.
한 가지 짚어 둔다. 2.5의 deep AutoEncoder는 비선형 층을 쌓아 표현력을 크게 키웠지만, 위 세 한계는 그대로 가진다. Deep AE도 latent에 명시적 prior가 없고, encoder가 입력을 한 점으로 매핑하며, 손실이 외부에서 정의된 reconstruction error이다. 곧 깊이를 더하는 것만으로는 generative model이 되지 않는다. VAE가 추가하는 것은 깊이가 아니라 확률 구조이다. 생성 모델 쪽으로는 latent에 prior $p(z)$를 두고 decoder를 분포 $p_\theta(x \mid z)$로 명시하며, 인지 모델 (encoder) 쪽으로는 출력을 한 점이 아니라 분포 $q_\phi(z \mid x)$로 바꾼다. 그리고 이 둘을 ELBO라는 단일 학습 목표로 묶는다. 아래 표는 AE (deep AE 포함) 와 VAE의 대비이다.
| 구성 요소 | AE | VAE |
|---|---|---|
| Latent 공간 | 명시적 prior 없음 | $p(z) = \mathcal{N}(0, I)$ 도입, KL 항으로 제약 |
| Encoder 출력 | 한 점 $z = f_\phi(x)$ | 분포 $q_\phi(z \mid x) = \mathcal{N}(\mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x)))$ |
| Decoder 출력 | 복원된 점 $\hat{x} = g_\theta(z)$ | 분포의 파라미터 $\eta = g_\theta(z)$, 그 위에서 $p_\theta(x \mid z)$ |
| 학습 손실 | 외부 정의 MSE $\|x - \hat{x}\|^2$ | Log likelihood의 lower bound (ELBO) |
두 모델의 가장 중요한 차이인 decoder 출력의 해석을 한 그림으로 본다.
두 모델 모두 decoder neural network 자체는 deterministic이다. 같은 $z$에 같은 출력이 나온다. 차이는 그 출력을 어떻게 해석하느냐에 있다. AE는 출력을 $x$ 자체로 보고, VAE는 출력을 $x$의 분포의 파라미터로 본다.
위 네 업데이트가 본 장의 모든 내용을 만들어 낸다. 흐름은 다음과 같다.
- 3.1 두 분포 모델: prior와 decoder. Latent 공간 위의 prior $p(z)$와 decoder가 정의하는 conditional $p_\theta(x \mid z)$를 적는다. 두 분포가 generative joint $p_\theta(z, x)$를 정의한다.
- 3.2 변분 근사: encoder의 분포. Encoder가 정의하는 분포 $q_\phi(z \mid x)$를 도입한다. 진짜 posterior가 계산 불가능한 상황에서 다루기 쉬운 분포족 안에서 근사하는 발상이다.
- 3.3 ELBO: 손실함수의 유도. 두 joint distribution와 Jensen 부등식으로부터 log likelihood의 lower bound인 ELBO를 얻는다. 이게 VAE의 학습 목표이다.
- 3.4 KL 항의 닫힌 형태. ELBO의 KL 항을 Gaussian에 대해 직접 계산한다.
- 3.5 학습 알고리즘: Reparameterization. Encoder의 sampling 단계가 differentiation 불가능한 문제를 reparameterization trick으로 해결한다. 학습 알고리즘 전체를 한 페이지로 정리한다.
- 3.6 학습된 VAE의 성질. 결과로 얻어지는 모델의 능력과 알려진 약점.
3.1 두 분포 모델
3.1.1 두 모델, 두 파라미터
VAE는 두 개의 neural network 기반 probabilistic model을 함께 학습한다.
- generative model $p_\theta(z, x)$: 데이터가 어떻게 만들어지는지를 기술한다. 파라미터 $\theta$를 가지며, decoder neural network $g_\theta$가 그 핵심이다.
- recognition model $q_\phi(z \mid x)$: 주어진 데이터를 보고 잠재 코드를 추론한다. 파라미터 $\phi$를 가지며, encoder neural network $f_\phi$가 그 핵심이다.
$\theta$와 $\phi$는 별개의 파라미터 집합이며, 두 모델이 짝을 이루어 동시에 학습된다. 본 절은 generative model을, 3.2에서는 recognition model을 다룬다.
3.1.2 joint distribution의 분해
generative model의 joint distribution는 확률의 chain rule에 의해 다음과 같이 쪼개진다.
이 식 자체는 어떤 joint distribution에도 성립하는 항등식이며 새로운 가정이 아니다. 실제 모델링 가정은 두 인수 $p(z)$와 $p_\theta(x \mid z)$에 어떤 분포를 넣을지에서 들어온다. 또한 이 식은 VAE의 생성 과정을 그대로 반영한다. 먼저 $z$를 $p(z)$에서 뽑고, 그 다음 $x$를 $p_\theta(x \mid z)$에서 뽑는다. 두 단계를 합치면 자연히 $(z, x)$의 joint distribution이 된다.
| 표기 | 이름 | 의미 |
|---|---|---|
| $p(z, x)$ | 결합 | $z$와 $x$가 동시에 나타날 확률 |
| $p(x \mid z)$ | 조건부 (생성) | $z$를 알 때 $x$가 어떻게 나오는가 |
| $p(z \mid x)$ | 조건부 (사후) | $x$를 봤을 때 $z$가 무엇이었는가 |
3.1.3 prior와 decoder의 출력 분포
두 분포 $p(z)$와 $p_\theta(x \mid z)$를 각각 정한다.
Prior $p(z)$. VAE에서는 거의 항상 prior로 standard Gaussian을 사용한다.
여기서 $d$는 잠재 차원으로 보통 32에서 256 정도이고, $0$은 zero vector, $I$는 $d \times d$ identity matrix이다. 일반적인 다변량 Gaussian의 정의는 mean $\mu \in \mathbb{R}^d$와 covariance $\Sigma \in \mathbb{R}^{d \times d}$ (positive definite)에 대해
$\mu = 0$, $\Sigma = I$를 대입하면
covariance가 대각이므로 각 차원이 독립이며 모두 1차원 standard Gaussian을 따른다. 직관적으로 latent space는 원점 근처에 부드럽게 퍼져 있는 isotropic 구름이며, 특별히 선호되는 방향이 없다.
Decoder $p_\theta(x \mid z)$. 도입부에서 본 대로 VAE의 decoder는 점 $\hat{x}$가 아니라 분포의 파라미터를 출력한다. 이 변화가 *왜 필요한지*를 한 번 더 풀어 본다. AE의 deterministic 함수 $\hat{x} = g_\theta(z)$를 VAE의 확률 모델 안에 그대로 가져오면, 학습 신호인 log likelihood가 정의되지 않는 상황이 발생한다. 그 진단으로부터 분포의 파라미터를 출력하는 형태가 도출된다.
가장 단순한 발상은 AE의 deterministic 함수 $g_\theta(z)$를 그대로 쓰는 것이다. 다만 이를 분포로 적으려면 약간의 변환이 필요하다. Deterministic 함수의 의미는 "$z$가 주어지면 $x$는 무조건 $g_\theta(z)$이고 다른 값은 확률 0이다"이다. 이를 PDF 형태로 적으려면 한 점 $g_\theta(z)$에서만 확률이 모이고 그 외 영역에서는 0인 분포가 필요하다. 이러한 분포를 Dirac delta라 부르며, 다음과 같이 정의한다.
한 점 $a$에서 무한히 뾰족하고 다른 점에서는 0이지만 적분하면 1이 되는 분포이다. 엄밀하게는 함수가 아니라 distribution(분포 이론에서의 generalized function)으로 정의되지만, 본 강의의 직관 수준에서는 위 형태로 충분하다. Deterministic 함수 $g_\theta(z)$를 조건부 분포로 적으면 다음과 같다.
그러나 이 분포로는 학습이 불가능하다. Log likelihood를 보면 이유가 분명하다. $x = g_\theta(z)$이면 $\log p_\theta(x \mid z) = +\infty$이고, 그 외에는 $-\infty$ (또는 정의되지 않음)이다. $g_\theta(z)$를 조금 움직여도 두 경우 모두 그대로이므로 "얼마나 가까운가"의 정보가 사라지고 gradient가 정의되지 않는다. 2.2의 Gaussian decoder가 $\log p \propto -\|x - g_\theta(z)\|^2$로 유한한 값을 가져 gradient가 잘 정의된 것과 대비된다.
한 가지 관련 관찰. Gaussian이나 Bernoulli 같은 exp 기저 PDF 가족의 멤버들은 log를 취하면 natural parameter에 대해 linear가 되어 gradient가 깔끔하게 정의된다. Dirac delta는 이 가족 밖의 degenerate 분포이며 mean이나 variance 같은 finite한 statistics로 표현되지 않는다. 학습 불가능의 직접 원인은 위 문단의 log·gradient 정의 실패이며, "exp family 밖"이라는 사실은 그것을 더 큰 그림에서 정리한 표현이다 (exp family 밖에도 학습 가능한 분포는 많다).
해법은 decoder가 $x$를 직접 출력하는 대신 $x$의 분포의 파라미터를 출력하는 것이다.
decoder neural network 자체는 여전히 deterministic이며 같은 $z$를 두 번 넣으면 같은 $\eta$가 나온다. 그러나 $\eta$는 $x$가 아니라 "$x$의 분포의 파라미터"이고, 진짜 $x$는 그 분포에서 확률적으로 뽑힌다. 학습 신호 $\log p(x \mid \eta)$가 잘 정의된 유한한 값이 된다.
또한 VAE는 $x$의 각 차원이 $z$ 조건부로 독립이라고 가정한다.
이는 $x$의 차원들 (예: 이미지의 픽셀들)이 실제로 독립이라는 뜻이 아니라, $z$가 이들 사이의 모든 의존성을 흡수했다는 가정이다. 만약 $z$가 "이 이미지는 7이며 약간 기울어졌다"는 정보를 모두 담고 있다면, $z$를 알고 난 뒤 한 픽셀이 다른 픽셀에 대해 더 알려줄 것이 없다는 발상이다.
출력 분포 가족의 통일성. 2.2에서 본 두 경우 (Gaussian decoder와 Bernoulli decoder)는 우연이 아니라 같은 패턴의 두 멤버이다. 두 분포는 모두 exp을 기저로 가지는 PDF 가족, 곧 exponential family의 멤버이며, 표준형은 다음과 같다.
여기서 $\eta$가 natural parameter, $T(x)$가 sufficient statistic, $A(\eta)$가 normalization을 담당하는 log-partition function, $h(x)$가 base measure이다. 두 가지 사실이 이 가족을 자연스러운 선택으로 만든다.
- Log를 취하면 $\eta$에 대해 linear가 되어 ($\log p = \eta^\top T(x) - A(\eta) + \log h(x)$) gradient 계산과 학습이 깔끔하다.
- Natural parameter $\eta$는 분포의 mean, variance 같은 친숙한 statistics와 직접 연결되어 있다. Gaussian (variance 고정): $\eta = \mu/\sigma^2$, sufficient statistic $T(x) = x$. Bernoulli: $\eta = \log\frac{\pi}{1-\pi}$ (logit), $T(x) = x$.
따라서 VAE의 decoder는 이 가족 안의 한 분포의 natural parameter를 출력하는 neural network로 통일적으로 설계된다. 2.2의 두 유도가 이 통일적 관점의 두 구체 사례이며, MSE는 Gaussian의 $-\log p$, BCE는 Bernoulli의 $-\log p$로부터 따라온 형태이다. Dirac delta가 학습 불가능했던 이유도 이 관점에서 한 번 더 명확해진다. Dirac delta는 exp 기저 PDF 가족의 멤버가 아니라 그 가족 밖에 있는 degenerate한 분포이며, mean과 variance 같은 finite한 statistics로 표현되지 않으므로 gradient를 통해 학습할 수 없다.
본 강의에서는 가장 자주 등장하는 두 경우만 다루지만, 같은 골격이 다음과 같이 일반화된다.
| 데이터 타입 | 분포 | Decoder의 마지막 activation | 손실 함수 |
|---|---|---|---|
| 이진 $\{0, 1\}$ | Bernoulli | sigmoid (또는 logit 출력) | BCE |
| 연속 실수 | Gaussian | 없음 (linear) | MSE |
| 범주형 ($K$개 클래스) | categorical | softmax | cross-entropy |
| 카운트 | Poisson | $\exp$ | Poisson NLL |
네 경우 모두 같은 골격이다. Decoder가 natural parameter를 출력하고, 적절한 exponential family 분포가 정의되며, negative log likelihood가 손실이 된다.
3.1.4 marginal likelihood와 추론 가능성
generative model이 정해졌으니 학습 목표를 적을 수 있다. 데이터 $\{x_1, \ldots, x_N\}$에 대한 log likelihood를 최대화한다.
합 형태와 expectation 형태는 같은 양을 다르게 표기한 것이다. 둘 사이를 잇는 분포 $p_D$는 데이터셋 자체를 분포로 표현한 것이다.
$x$의 marginal likelihood는 latent variable에 대한 integral으로 표현되는데, 이 integral은 일반적으로 계산할 수 없다. $z$가 수십에서 수백 차원이고 decoder가 비선형 neural network이므로 닫힌 형태가 존재하지 않으며, 수치integral도 차원의 저주 때문에 불가능하다. 몬테카를로 추정 $\frac{1}{S}\sum_s p_\theta(x \mid z^{(s)})$, $z^{(s)} \sim p(z)$도 원리상 가능하지만, $p(z)$에서 무작위로 뽑은 대부분의 $z$가 데이터를 잘 설명하지 못해 variance가 매우 크다. 같은 integral이 Bayes theorem의 분모로 등장하므로 posterior $p_\theta(z \mid x) = p_\theta(x \mid z) p(z) / p_\theta(x)$도 직접 계산할 수 없다.
3.2 변분 근사
3.2.1 추론하고 싶은 두 양
학습과 추론을 위해 두 양이 필요하다. 첫째는 데이터의 marginal likelihood $p_\theta(x)$로, 학습 목표 그 자체이다. 둘째는 posterior $p_\theta(z \mid x)$로, "이 데이터를 만들어낸 잠재 코드의 분포"이다. 두 양 모두 같은 integral 때문에 막혀 있다.
3.2.2 approximate inference의 두 갈래
이 문제에 대한 표준적인 우회로는 approximate inference이며 크게 두 갈래로 나뉜다.
- MCMC (Markov Chain Monte Carlo): posterior를 샘플링으로 근사한다. 점근적으로 정확하지만 매 데이터마다 체인을 돌려야 해서 느리다.
- Variational inference (VI): 다루기 쉬운 분포족 $q$ 안에서 posterior에 가장 가까운 분포를 찾는다. 빠르지만 분포족이 진짜 사후를 포함하지 못하면 편향이 남는다.
VAE는 variational inference을 채택한다.
3.2.3 Amortized Inference
전통적인 variational inference은 데이터 한 점 $x_i$마다 variational parameter $\phi_i$를 별도로 optimization을 수행한다. 데이터셋 크기가 $N$이면 $N$개의 optimization 문제를 풀어야 하므로 대규모 학습에는 부적절하다.
VAE의 핵심 아이디어는 어차피 $x \mapsto q(z \mid x)$라는 함수를 매번 찾아야 한다면, 그 함수 자체를 neural network으로 학습하자는 것이다. 이를 amortized inference라 부르며("amortized"는 회계 용어로 "분할 상환"이라는 뜻이다), 학습 비용을 한 번 치르면 새로운 $x$에 대해서는 encoder를 한 번 통과시키는 비용만으로 사후 근사를 얻을 수 있다.
$f_\phi$가 recognition network, 또는 그냥 encoder이다. 입력 $x$를 받아 잠재 분포의 파라미터를 출력하는 neural network이다.
3.2.4 variational posterior의 정의
VAE에서는 recognition model도 거의 항상 Gaussian으로 둔다.
encoder $f_\phi$는 두 벡터를 출력한다. mean $\mu_\phi(x) \in \mathbb{R}^d$와 variance $\sigma_\phi^2(x) \in \mathbb{R}_{>0}^d$이다. 실제 구현에서는 variance가 양수가 되도록 보장하기 위해 $\log \sigma^2$를 출력한 뒤 $\exp$를 씌운다.
covariance가 대각행렬이라는 가정을 mean-field approximation이라 부른다. 이는 잠재 차원들이 $x$ 조건부로 독립이라는 뜻이다. 진짜 posterior $p_\theta(z \mid x)$는 차원 간 correlation이 있을 수 있지만, 계산 가능성을 위해 대각 Gaussian으로 근사하는 단순화이다.
식 (21.6)의 $\approx$ 기호는 막연한 "비슷함"이 아니라 정확한 의미를 가진다. 진짜 posterior는 계산 불가능하므로, 다루기 쉬운 분포족 안에서 진짜 사후에 가장 가까운 것을 찾는다는 뜻이다. 가까움의 척도는 KL divergence이며, 이를 최소화하는 일이 ELBO를 최대화하는 일과 정확히 동치이다 (3.3.4).
여기까지의 구조를 한 장의 그림으로 요약하면 다음과 같다. 생성 방향과 추론 방향이 한 사이클을 이룬다.
3.3 두 joint distribution과 ELBO
3.3.1 두 joint distribution
3.1.2에서 본 generative joint $p_\theta(z, x) = p(z)\, p_\theta(x \mid z)$의 짝으로, 데이터 분포와 encoder를 묶은 분포를 정의할 수 있다.
이 분포에서 한 쌍 $(z, x)$를 뽑는 절차는 다음과 같다. 먼저 데이터셋에서 $x$를 균등하게 뽑고 ($x \sim p_D$, 3.1.4 sidenote), 그 $x$를 encoder에 통과시켜 $z$를 뽑는다 ($z \sim q_\phi(z \mid x)$). VAE의 두 neural network가 대칭으로 만들어 내는 두 joint distribution이 정리된다.
| 분포 | 정의 | 샘플링 절차 |
|---|---|---|
| Generative joint $p_\theta(z, x)$ | $p(z)\, p_\theta(x \mid z)$ | $z \sim p(z)$ 뽑고, decoder로 $x$ 뽑기 |
| Inference joint $q_{D, \phi}(z, x)$ | $p_D(x)\, q_\phi(z \mid x)$ | $x \sim p_D$ 뽑고, encoder로 $z$ 뽑기 |
한 분포는 모델이 가정하는 "생성 방향"의 결합이고, 다른 한 분포는 데이터와 encoder가 함께 만드는 "추론 방향"의 결합이다. VAE 학습의 핵심 직관은 이 두 joint distribution이 서로 닮아지도록 만드는 것으로 요약된다. 3.3.4에서 보듯 두 결합 사이의 KL이 ELBO와 직접 연결된다.
실용적인 효과 하나는 이중 expectation이 단일 expectation으로 표현된다는 점이다.
이는 chain rule의 또 다른 얼굴이며, VAE의 목적함수를 단일 분포 위의 expectation으로 깔끔하게 적을 수 있게 한다.
3.3.2 Jensen 부등식과 ELBO
두 joint distribution를 손에 두고 log likelihood $\log p_\theta(x)$를 분해한다. 직접 다루기 어렵기 때문에 다른 형태로 옮긴다. 핵심 도구는 Jensen 부등식이다.
$\varphi : \mathbb{R} \to \mathbb{R}$가 concave function이고 $X$가 integral 가능한 random variable이면,
$$\varphi\!\big(\mathbb{E}[X]\big) \;\geq\; \mathbb{E}\!\big[\varphi(X)\big]$$이 성립한다. 등호는 $X$가 거의 확실히 상수일 때, 또는 $\varphi$가 $X$의 지지집합 위에서 linear일 때 성립한다.
$\log$는 정의역 $(0, \infty)$에서 concave function이므로 $\log \mathbb{E}[X] \geq \mathbb{E}[\log X]$가 따라 나온다. Concave function의 그래프가 그 위에 그은 직선보다 아래에 있다는 기하학적 사실의 확률 버전이다.
이 부등식을 임의의 분포 $q_\phi(z \mid x)$에 대해 다음과 같이 적용한다.
두 번째 줄은 분자와 분모에 $q_\phi(z \mid x)$를 곱한 단순 변형이고 ($q_\phi$가 0이 아닌 영역에서 정의되었다고 가정), 세 번째 줄은 expectation의 정의이다. 네 번째 줄에서 보조정리 3.1을 적용했다. 다섯째와 여섯째 줄은 joint distribution를 chain rule로 분해한 결과이다. 마지막 두 줄에서는 $\log$의 분자가 prior $p(z)$, 분모가 variational posterior $q_\phi(z \mid x)$인 비가 등장하므로, 이를 부호를 뒤집어 KL로 정리한다.
이 단계가 ELBO 식에 "음의 KL"이 등장하는 이유이다. KL의 정의 $D_{\text{KL}}(q \| p) = \mathbb{E}_q[\log(q/p)]$에서 분자와 분모의 순서가 식과 맞지 않아 부호를 뒤집어야 한다.
마지막 줄이 Evidence Lower BOund (ELBO)이다. log likelihood의 lower bound이며, 이 값을 최대화하면 log likelihood 자체도 최소한 그만큼 커지도록 강제된다. 한편 Jensen 부등식의 등호 조건으로부터, ELBO와 log likelihood가 정확히 같아지는 시점은 $p_\theta(x, z) / q_\phi(z \mid x)$가 $z$에 의존하지 않는 상수일 때이다. 이 조건은 $q_\phi(z \mid x) \propto p_\theta(x, z)$, 곧 $q_\phi(z \mid x) = p_\theta(z \mid x)$일 때 만족된다. 즉 variational posterior가 진짜 사후와 일치할 때 ELBO가 최대화된다(이 사실은 3.3.4에서 다시 명시적으로 확인한다).
VAE의 손실함수는 ELBO의 음수이다. 학습은 $\phi$와 $\theta$에 대해 $-\mathcal{L}_{\text{ELBO}}$를 최소화하는 과정이다.
3.3.3 두 항의 의미
ELBO를 구성하는 두 항은 직관적으로 다음과 같이 해석된다.
reconstruction 항 $\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x \mid z)]$: $q_\phi$로부터 뽑은 $z$로부터 $x$를 얼마나 잘 복원하는지를 나타낸다. Gaussian decoder $p_\theta(x \mid z) = \mathcal{N}(g_\theta(z), \sigma^2 I)$의 경우 이 항은 다음과 같이 풀린다.
Negative log likelihood가 정확히 MSE reconstruction loss의 형태이다. 따라서 VAE의 reconstruction term은 AutoEncoder의 reconstruction loss와 동일한 양이며, 단지 decoder output 분포의 negative log likelihood라는 형태로 표현된다는 점만 다르다.
KL term $D_{\text{KL}}(q_\phi(z|x) \| p(z))$: encoder가 출력한 분포가 prior로부터 얼마나 벗어났는지를 측정한다. 이 항은 모든 입력에 대해 $q_\phi(z|x)$가 $p(z) = \mathcal{N}(0, I)$ 근처에 머무르도록 제약하며, encoder가 latent space의 임의의 위치로 발산하는 것을 막는다. 정보이론 관점에서 이 양은 "잠재 코드 $z$가 입력 $x$에 대해 담고 있는 information의 양"으로도 해석되며, β-VAE에서 rate로 재정의된다(4.3).
두 항은 반대 방향으로 작용한다. Reconstruction term은 입력마다 변별력 있는 잠재 표현을 요구하므로 잠재 분포들을 서로 분리시키고, KL term은 모든 분포를 prior에 가깝게 제약한다. 두 효과가 균형을 이룬 지점에서 latent space는 prior에 가까운 분포로 채워지면서도 각 입력의 정보를 구분할 수 있는 형태가 된다.
3.3.4 또 다른 분해
ELBO와 log likelihood 사이의 정확한 차이를 다른 각도에서 본다. 이 차이가 variational posterior와 진짜 posterior 사이의 KL과 같다는 사실이 한 식으로 떨어진다.
출발점은 같다. ELBO의 정의에 ELBO 식을 대입한다.
$$\mathcal{L}_{\text{ELBO}} \;=\; \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log \frac{p_\theta(x, z)}{q_\phi(z \mid x)}\right]$$$\log p_\theta(x)$는 $z$에 대해 상수이므로 $\mathbb{E}_{q_\phi(z \mid x)}[\log p_\theta(x)] = \log p_\theta(x)$이다. 이 사실을 이용해 두 양의 차이를 하나의 expectation으로 묶는다.
\begin{aligned} \log p_\theta(x) - \mathcal{L}_{\text{ELBO}} &= \mathbb{E}_{q_\phi(z \mid x)}\!\big[\log p_\theta(x)\big] - \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log \frac{p_\theta(x, z)}{q_\phi(z \mid x)}\right] \\[4pt] &= \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log p_\theta(x) - \log \frac{p_\theta(x, z)}{q_\phi(z \mid x)}\right] \\[4pt] &= \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log \frac{p_\theta(x) \, q_\phi(z \mid x)}{p_\theta(x, z)}\right] \end{aligned}이제 joint distribution를 다른 방향으로 분해한다. Chain rule을 $p_\theta(x, z) = p_\theta(z \mid x)\, p_\theta(x)$ 형태로 적용하면 분모의 $p_\theta(x)$가 분자와 약분된다.
\begin{aligned} &= \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log \frac{p_\theta(x) \, q_\phi(z \mid x)}{p_\theta(z \mid x)\, p_\theta(x)}\right] \\[4pt] &= \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log \frac{q_\phi(z \mid x)}{p_\theta(z \mid x)}\right] \\[4pt] &= D_{\text{KL}}\!\big(q_\phi(z \mid x) \,\|\, p_\theta(z \mid x)\big) \end{aligned}따라서 다음 관계가 성립한다.
이 관계에서 두 가지 사실이 드러난다. 첫째, ELBO는 log likelihood에서 variational posterior와 진짜 posterior 사이의 KL만큼 작다. KL은 항상 0 이상이므로 ELBO가 log likelihood의 lower bound임이 다시 확인된다 (3.3에서 Jensen 부등식으로 본 사실의 다른 표현이다). 둘째, ELBO를 최대화하면 동시에 log likelihood가 최대화되고 variational posterior가 진짜 posterior에 가까워진다. 두 효과가 하나의 objective에 함께 포함되어 있어 한 번의 optimization으로 둘 다 달성된다. 또한 3.3 끝에서 언급한 "ELBO가 log likelihood와 일치하는 시점"이 바로 이 KL이 0인 시점, 곧 $q_\phi(z \mid x) = p_\theta(z \mid x)$인 시점임이 명시적으로 확인된다.
3.3.1에서 정의한 두 joint distribution(generative joint $p_\theta(z, x)$와 inference joint $q_{D, \phi}(z, x) = p_D(x) q_\phi(z \mid x)$) 사이의 KL과 ELBO의 관계도 짚어 둔다. 데이터셋 전체에 대해 위 등식의 양변을 $x \sim p_D$에 대해 expectation을 취하면
우변을 두 joint distribution의 KL로 다시 적으면 (chain rule을 적용하고 $p_D(x)$가 양쪽 분포에 공통으로 나타남을 이용하면) $D_{\text{KL}}(q_{D, \phi}(z, x) \,\|\, p_\theta(z, x))$에서 $-\mathbb{E}_{x \sim p_D}[\log p_\theta(x)]$를 더하고 빼는 형태로 정리된다. 결국 ELBO를 최대화하는 것은 두 joint distribution 사이의 KL을 줄이는 작업과 동등하며, 이것이 3.3.1에서 언급한 "두 joint distribution이 서로 닮아지도록 만드는" 의미이다.
3.4 ELBO 항의 분석: Gaussian KL의 닫힌 형태
두 Gaussian 사이의 KL divergence는 닫힌 형태로 계산된다. $q_\phi(z \mid x) = \mathcal{N}(\mu, \text{diag}(\sigma^2))$이고 $p(z) = \mathcal{N}(0, I)$일 때 (둘 다 $d$차원), 다음 식이 성립한다.
먼저 KL의 정의에서 본다.
$$D_{\text{KL}}(q \,\|\, p) \;=\; \mathbb{E}_{q}\!\big[\log q(z) - \log p(z)\big]$$두 분포가 모두 대각 covariance Gaussian이므로 각 차원이 독립이다. 따라서 KL은 차원별 KL의 합으로 분해된다.
$$D_{\text{KL}}\!\big(q(z) \,\|\, p(z)\big) \;=\; \sum_{j=1}^{d} D_{\text{KL}}\!\big(\mathcal{N}(\mu_j, \sigma_j^2) \,\|\, \mathcal{N}(0, 1)\big)$$이제 한 차원의 KL을 계산한다. 1차원 Gaussian의 로그 밀도는
$$\log \mathcal{N}(z \mid \mu, \sigma^2) = -\tfrac{1}{2}\log(2\pi\sigma^2) - \frac{(z - \mu)^2}{2\sigma^2}$$이를 정의에 대입하면
\begin{aligned} D_{\text{KL}}\!\big(\mathcal{N}(\mu, \sigma^2) \,\|\, \mathcal{N}(0, 1)\big) &= \mathbb{E}_{q}\!\left[-\tfrac{1}{2}\log(2\pi\sigma^2) - \frac{(z-\mu)^2}{2\sigma^2} + \tfrac{1}{2}\log(2\pi) + \frac{z^2}{2}\right] \\[4pt] &= -\tfrac{1}{2}\big(\log(2\pi) + \log \sigma^2\big) + \tfrac{1}{2}\log(2\pi) - \mathbb{E}_q\!\left[\frac{(z-\mu)^2}{2\sigma^2}\right] + \mathbb{E}_q\!\left[\frac{z^2}{2}\right] \\[4pt] &= -\tfrac{1}{2}\log \sigma^2 - \mathbb{E}_q\!\left[\frac{(z-\mu)^2}{2\sigma^2}\right] + \mathbb{E}_q\!\left[\frac{z^2}{2}\right] \end{aligned}두 번째 등호에서 $\log(2\pi\sigma^2) = \log(2\pi) + \log \sigma^2$로 분리한 뒤, $\log(2\pi)$ 항이 상쇄되어 세 번째 줄을 얻는다.
이제 두 expectation을 각각 정리한다. Variance의 정의 $\mathbb{E}_q[(z-\mu)^2] = \sigma^2$로부터
$$\mathbb{E}_q\!\left[\frac{(z-\mu)^2}{2\sigma^2}\right] = \frac{\sigma^2}{2\sigma^2} = \tfrac{1}{2}$$또한 variance의 정의를 풀어쓰면 $\mathbb{E}_q[z^2] = \operatorname{Var}_q[z] + (\mathbb{E}_q[z])^2 = \sigma^2 + \mu^2$이므로
$$\mathbb{E}_q\!\left[\frac{z^2}{2}\right] = \frac{\sigma^2 + \mu^2}{2}$$두 결과를 대입하면
$$D_{\text{KL}}\!\big(\mathcal{N}(\mu, \sigma^2) \,\|\, \mathcal{N}(0, 1)\big) = -\tfrac{1}{2}\log \sigma^2 - \tfrac{1}{2} + \frac{\sigma^2 + \mu^2}{2} = \tfrac{1}{2}\big(\mu^2 + \sigma^2 - \log \sigma^2 - 1\big)$$차원별 합을 취하면 본문의 식이 그대로 나온다.
식의 각 항은 직관적으로 다음 의미를 가진다.
- $\mu_j^2$: Mean이 0에서 벗어난 정도에 대한 페널티. $\mu_j$가 prior의 중심 0에서 멀어질수록 KL이 커진다.
- $\sigma_j^2 - \log \sigma_j^2 - 1$: $\sigma_j^2$의 함수로 보면 $\sigma_j^2 = 1$일 때 0이 되는 convex function이다. differentiation으로 확인하면 $f(s) = s - \log s - 1$이 $s = 1$에서 minimum 0을 가지며, $s < 1$이나 $s > 1$ 양쪽에서 모두 페널티가 부과된다. 즉 variance가 prior의 1에서 벗어나면 양방향으로 페널티가 부과된다.
각 차원이 독립이고 모두 닫힌 형태로 계산되므로 differentiation도 직접 가능하다. 이 점이 Gaussian을 variational posterior로 선택하는 실용적 이유이다. KL이 0이 되려면 $\mu_j = 0$과 $\sigma_j^2 = 1$이 동시에 만족되어야 하는데, 이는 encoder의 출력이 정확히 standard Gaussian을 따라야 한다는 의미이다. 그러나 이 경우 모든 입력이 같은 분포로 매핑되어 reconstruction이 불가능해진다. 따라서 학습이 진행되는 동안 KL은 0이 아닌 양의 값에서 두 효과가 균형을 이룬다.
3.5 학습 알고리즘: Reparameterization
3.5.1 학습의 기술적 장벽: 샘플링과 backpropagation
지금까지의 논의로 VAE의 학습 목표(ELBO 최대화)와 그 의미는 정리되었다. 그러나 막상 gradient 기반 optimization로 ELBO를 풀려 하면 미묘한 기술적 문제가 등장한다. reconstruction 항을 다시 본다.
이 expectation을 gradient로 optimization하려면 $\phi$에 대한 differentiation이 필요하다. 그런데 expectation을 정의하는 분포 자체가 $\phi$에 의존한다. $z$를 $q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \sigma^2_\phi(x))$에서 뽑은 다음 decoder에 통과시키는 것이 forward 과정인데, "분포에서 뽑는다(샘플링)"는 연산은 결정론적 함수가 아니다. 같은 $\mu, \sigma$에 대해서도 매번 다른 $z$가 나온다. 따라서 이 연산은 differentiation이 불가능하며, chain rule을 통해 encoder까지 gradient를 흘려보낼 수 없다.
3.5.2 Gaussian의 linear transformation: 도구 준비
3.5.1에서 본 문제는 "$z$를 $q_\phi(z\mid x)$에서 뽑는다"는 연산이 differentiation 불가능하다는 것이었다. 해법을 도입하기 전에 그 해법의 수학적 토대인 Gaussian의 linear transformation 성질부터 정리한다. 다음 명제가 3.5.3의 출발점이다.
random variable $\epsilon$이 다변량 Gaussian $\mathcal{N}(m, S)$를 따르고, 상수 행렬 $A$와 벡터 $b$에 대해 $z = A\epsilon + b$로 정의하면, $z$ 또한 Gaussian을 따르며 그 모수는 다음과 같다.
$$z \sim \mathcal{N}\!\big(Am + b,\; A S A^\top\big)$$식의 mean은 $A$가 expectation에 그대로 작용한 결과이다. 핵심은 covariance가 $ASA^\top$이라는 점, 곧 $A$가 양쪽에서 작용하되 한쪽이 전치되어 들어간다는 점이다.
mean은 expectation의 선형성으로부터 $\mathbb{E}[z] = A\mathbb{E}[\epsilon] + b = Am + b$가 곧장 따라온다. covariance는 정의를 그대로 전개한다.
\begin{aligned} \operatorname{Cov}(z) &= \mathbb{E}\!\left[(z - \mathbb{E}[z])(z - \mathbb{E}[z])^\top\right] \\[4pt] &= \mathbb{E}\!\left[A(\epsilon - m)\,\big(A(\epsilon - m)\big)^\top\right] \\[4pt] &= \mathbb{E}\!\left[A(\epsilon - m)(\epsilon - m)^\top A^\top\right] \\[4pt] &= A\,\mathbb{E}\!\left[(\epsilon - m)(\epsilon - m)^\top\right]\,A^\top \\[4pt] &= A\,S\,A^\top \end{aligned}둘째 줄에서 $z - \mathbb{E}[z] = A(\epsilon - m)$을 대입했고, 셋째 줄에서 행렬 곱의 전치 규칙 $(AB)^\top = B^\top A^\top$을 사용했다. 넷째 줄에서 $A$와 $A^\top$이 상수이므로 expectation 바깥으로 빠져나갔다. (Gaussian성 자체의 보존은 모멘트 생성 함수로 따로 확인된다.)
이 명제를 VAE에 응용할 두 특수 경우를 미리 정리한다. 둘 다 $\epsilon \sim \mathcal{N}(0, I)$, 곧 $m = 0$, $S = I$인 경우이다.
두 경우 모두 같은 패턴이다. standard Gaussian noise $\epsilon$에 행렬 $A$를 곱하고 mean $\mu$를 더한다. 차이는 $A$의 구조이다. (a)는 $A$가 대각행렬이라 차원별 곱($\sigma \odot \epsilon$)이 되고, (b)는 $A$가 일반 lower triangular이라 차원 간 correlation까지 표현한다. 사실 (a)는 (b)에서 $L = \operatorname{diag}(\sigma)$로 둔 특수 케이스이며, 그 결과 covariance $\Sigma = LL^\top = \operatorname{diag}(\sigma^2)$가 대각이 된다. 본 강의의 기본 가정인 mean-field variational posterior(3.2.4)가 이 (a)에 해당한다. (b)에 등장하는 일반 행렬 $L$은 Cholesky 분해로부터 얻는다.
positive definite 대칭 행렬 $\Sigma \in \mathbb{R}^{d \times d}$에 대해 다음을 만족하는 lower triangular matrix $L$이 유일하게 존재한다.
$$\Sigma = L L^\top, \qquad L = \begin{pmatrix} \ell_{11} & 0 & \cdots & 0 \\ \ell_{21} & \ell_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ \ell_{d1} & \ell_{d2} & \cdots & \ell_{dd} \end{pmatrix}, \quad \ell_{kk} > 0$$$L$은 $d(d+1)/2$개의 자유 파라미터를 가지며, 직관적으로 "행렬의 제곱근"에 해당한다.
Cholesky 분해의 중요성은 두 방향에서 나온다. 첫째, 어떤 lower triangular matrix $L$(대각 성분이 양수)에 대해서도 $LL^\top$이 자동으로 positive definite 대칭 행렬이 된다. 따라서 neural network가 covariance $\Sigma$를 직접 출력하는 대신 $L$을 출력하도록 두면, "출력이 covariance으로서 유효한가"를 따로 검사할 필요가 없어진다. 둘째, 명제 3.1의 (b)에 따라 $z = L\epsilon + \mu$가 곧바로 원하는 $\mathcal{N}(\mu, \Sigma)$의 샘플이 된다. covariance를 표현하는 문제와 differentiation 가능한 샘플링 문제가 같은 $L$로 한꺼번에 풀린다.
본 강의는 기본적으로 (a) 대각 Gaussian 경우만 다룬다. (b) 일반 covariance는 3.5.4 학습 알고리즘에서 encoder 출력을 확장하는 변종으로 짧게 언급한다.
3.5.3 Reparameterization Trick
이제 3.5.1의 문제로 다시 본다. encoder가 출력한 $q_\phi(z \mid x) = \mathcal{N}\!\big(\mu_\phi(x),\, \operatorname{diag}(\sigma_\phi^2(x))\big)$로부터 $z$를 뽑되, $\phi$에 대한 gradient가 흐를 수 있어야 한다. 직접 샘플링은 differentiation 불가능하므로, 명제 3.1의 (a)를 우회로로 사용한다.
Kingma와 Welling [13]의 reparameterization trick은 Gaussian 샘플링을 두 단계로 분해하는 것이다.
- standard Gaussian에서 noise를 뽑는다. $\epsilon \sim \mathcal{N}(0, I)$. 이 단계는 확률적이지만, 분포가 $\phi$와 무관하다.
- 결정론적 변환으로 latent variable를 구성한다. $z = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon$. 이 단계는 $\phi$에 대해 differentiation 가능하다.
이렇게 정의된 $z$가 정확히 $\mathcal{N}\!\big(\mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x))\big)$를 따른다는 사실은 명제 3.1의 (a)로부터 즉시 따라온다. 곧 encoder가 출력한 분포에서 뽑은 것과 분포적으로 동일하다.
핵심 변화는 무작위성이 $\epsilon$이라는 외부 noise로 격리되었다는 점이다. $z$는 이제 $(\mu_\phi(x), \sigma_\phi(x), \epsilon)$의 결정론적 함수이며, $\epsilon$은 입력 데이터처럼 외부에서 들어오는 양일 뿐 학습 대상이 아니다. 따라서 $\nabla_\phi z$가 잘 정의되고, chain rule이 encoder 끝까지 흐른다.
이 결과를 적용하면 ELBO의 gradient가 다음과 같이 표현된다.
안쪽의 gradient는 결정론적 계산 그래프 위에서 자동differentiation으로 곧장 계산된다. 실제 구현에서는 mini-batch마다 $\epsilon$을 한 번씩만 뽑는 Monte Carlo 추정(샘플 수 $S = 1$)으로도 충분하며, 이 추정은 unbiased이다.
3.5.4 학습 알고리즘 pseudocode
지금까지 정리한 모든 요소가 한 페이지의 의사코드로 모인다. 데이터 한 점 $x$를 대상으로 한 사이클을 적으면 다음과 같다. 실무에서는 미니배치 위에서 mean을 취해 같은 형태로 작동한다.
출력: 학습된 파라미터 $\theta$ (decoder), $\phi$ (encoder)
2: repeat
3: $x \sim p_D$ // 데이터셋에서 한 점
4: $\epsilon \sim \mathcal{N}(0, I)$ // 외부 noise
5: $(\mu, \log \sigma) \leftarrow f_\phi(x)$ // encoder forward
6: $\sigma \leftarrow \exp(\log \sigma)$
7: $z \leftarrow \mu + \sigma \odot \epsilon$ // reparameterization (명제 3.1a)
8: $\eta_x \leftarrow g_\theta(z)$ // decoder forward, natural parameter 출력
9: $\log q_\phi(z\mid x) \leftarrow -\sum_{k=1}^{d} \!\left[\tfrac{1}{2}\epsilon_k^2 + \tfrac{1}{2}\log(2\pi) + \log \sigma_k\right]$
10: $\log p(z) \leftarrow -\sum_{k=1}^{d} \!\left[\tfrac{1}{2} z_k^2 + \tfrac{1}{2}\log(2\pi)\right]$
11: $\log p_\theta(x\mid z) \leftarrow$ (Gaussian이면 MSE 형태, Bernoulli면 BCE 형태)
12: $\mathcal{L} \leftarrow \log p_\theta(x\mid z) + \log p(z) - \log q_\phi(z\mid x)$ // ELBO 단일 샘플 추정
13: $\theta \leftarrow \theta + \eta\, \nabla_\theta \mathcal{L}$
14: $\phi \leftarrow \phi + \eta\, \nabla_\phi \mathcal{L}$
15: until 수렴
의사코드의 각 줄이 3.5.1~3.5.3의 어느 부분에 대응하는지 짚어 둔다.
Line 3. $x \sim p_D$는 3.1.4 sidenote의 경험적 분포에서 한 점을 뽑는 동작이며, 실무적으로는 데이터셋에서 한 점을 무작위로 고르는 것과 같다. 미니배치 위에서는 손실을 mean낸다.
Lines 4, 7. 3.5.3 reparameterization trick의 실행이다. 외부 noise $\epsilon$을 먼저 뽑고, 결정론적 변환 $\mu + \sigma \odot \epsilon$으로 $z$를 만든다. 3.5.2 명제 3.1의 (a)에 의해 이 $z$는 $\mathcal{N}(\mu, \operatorname{diag}(\sigma^2))$를 따른다.
Line 5. encoder가 $\sigma$ 대신 $\log \sigma$를 출력하는 이유는 $\sigma > 0$을 자동으로 보장하기 위함이다. 실제 학습 시 $\sigma$가 음수가 되는 사고를 막는다.
Line 8. decoder가 출력하는 $\eta_x$는 데이터 분포의 natural parameter이다(3.1.3). Gaussian decoder라면 mean, Bernoulli decoder라면 logit이다.
Line 9: $\log q_\phi(z \mid x)$의 닫힌 형태. 3.1.3에서 본 다변량 Gaussian의 정의를 그대로 적용한다. 대각 covariance $\Sigma = \text{diag}(\sigma^2)$인 경우 $|\Sigma| = \prod_k \sigma_k^2$이고 $\Sigma^{-1} = \text{diag}(1/\sigma^2)$이므로
여기서 $z_k - \mu_k = \sigma_k \epsilon_k$이므로 $(z_k - \mu_k)^2 / \sigma_k^2 = \epsilon_k^2$로 깔끔하게 떨어진다. 또한 $\log \sigma_k^2 = 2 \log \sigma_k$이므로
$z$ 자체를 다시 쓰지 않고 $\epsilon$과 $\sigma$만으로 표현되는 점이 핵심이다. Reparameterization으로 인해 $\log q_\phi(z \mid x)$의 계산이 단순해진 결과이다.
Line 10: $\log p(z)$의 닫힌 형태. prior가 standard Gaussian $\mathcal{N}(0, I)$이므로 정의 그대로
학습 가능한 파라미터가 없다.
Line 11: $\log p_\theta(x \mid z)$의 형태. 데이터 타입에 따라 2.2의 두 유도 중 하나가 들어간다. Gaussian decoder라면 $-\|x - g_\theta(z)\|^2 / (2\sigma^2) + \text{const}$(MSE 형태), Bernoulli decoder라면 $\sum_d [x_d \log \pi_d + (1-x_d)\log(1-\pi_d)]$(BCE 형태)이다.
Line 12: 단일 샘플 Monte Carlo 추정. 본래의 ELBO는 $\mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z) + \log p(z) - \log q_\phi(z\mid x)]$의 expectation이다. 한 번의 reparameterization 샘플로 얻은 값이 이 expectation의 unbiased 추정이며, 실무에서는 $S = 1$ 샘플로도 학습이 충분히 안정적이다. 한편 3.3의 표준 ELBO 형태 $\mathbb{E}_q[\log p_\theta(x\mid z)] - D_{\text{KL}}(q_\phi(z\mid x) \,\|\, p(z))$를 쓰면 KL 항을 3.4의 닫힌 형태로 직접 계산할 수 있어 추정 variance가 더 줄어든다. 두 방식 모두 같은 ELBO를 가리킨다.
Lines 13–14: 부호 관습. ELBO를 최대화해야 하므로 식상으로는 gradient ascent이다. 실무에서는 $-\mathcal{L}$을 손실(loss)로 정의하고 표준 gradient descent를 돌리는 편이 라이브러리(PyTorch, JAX 등)와의 궁합이 좋다. 부호만 다를 뿐 동치이다.
3.6 학습된 VAE의 성질
3.6.1 능력
학습이 끝난 VAE는 다음의 작업을 수행할 수 있다.
- reconstruction: 입력 $x$를 encoder로 compression(mean값 $\mu_\phi(x)$ 사용)한 후 decoder로 복원한다. AE와 같은 방식이다.
- 생성: prior $p(z) = \mathcal{N}(0, I)$에서 $z$를 뽑아 decoder에 통과시킨다. 학습 데이터에 없던 새로운 샘플이 만들어진다.
- latent space 보간: 두 입력의 인코딩 $z_1, z_2$ 사이를 선형으로 보간한 $z_t = (1-t)z_1 + t z_2$를 디코딩하면 부드럽게 변하는 일련의 이미지를 얻는다.
- 잠재 산술: latent space에서 "안경 쓴 사람의 $z$ − 안경 없는 사람의 $z$ + 다른 사람의 $z$" 같은 산술 연산이 의미를 가지는 경우가 있다.
겉으로 보면 VAE의 구조는 일반 AutoEncoder와 같다. encoder로 압축하고 decoder로 복원하는 것이다. 그래서 이름에도 "autoencoder"가 들어간다. 다만 둘은 다음과 같이 다르다.
| 항목 | 일반 AE | VAE |
|---|---|---|
| encoder 출력 | 결정론적 벡터 $z$ | 확률 분포 $q_\phi(z \mid x)$ |
| 학습 목표 | reconstruction 오차 최소화 | ELBO 최대화 (reconstruction 항 + KL 항) |
| latent space 구조 | 구조에 대한 보장 없음 | prior에 가깝게 정렬됨 |
| 새 샘플 생성 | 불가 | 가능 ($z \sim p(z)$를 뽑아 디코딩) |
| probabilistic model인가 | 아니다 (회귀 문제) | 그렇다 ($p_\theta(x)$를 학습) |
한 줄로 정리하면 VAE는 결정론적 AE의 확률적 일반화이며, 거기에 KL 정규화가 더해진 형태이다. 일반 AE의 야망이 "데이터를 잘 복원하는 표현을 학습"하는 데 있다면, VAE의 야망은 "데이터의 진짜 확률 분포 $p(x)$를 학습해 새 샘플을 생성"하는 데 있다.
3.6.2 알려진 약점: 흐릿한 샘플
VAE의 가장 잘 알려진 약점은 생성된 sample이 흐릿하다는 점이다. GAN이나 diffusion model이 만들어낸 이미지와 비교하면 detail이 부족하고 부드럽게 뭉개진 양상을 보인다. 이 현상은 Gaussian decoder와 MSE loss라는 조합 자체로부터 따라 나온다.
Gaussian decoder의 음의 log likelihood는 MSE에 비례한다. 그런데 같은 잠재 코드 $z$로 매핑되는 여러 입력 $x$가 있을 때(encoder가 비슷한 이미지를 같은 영역의 분포로 묶으면 그렇게 된다), MSE를 최소화하는 decoder의 출력은 그 입력들의 mean이 된다. 그리고 이미지의 mean은 디테일이 서로 어긋나 상쇄되기 때문에 흐릿한 형태로 나타난다.
이 약점을 다루는 방향은 여러 갈래로 나뉜다. weight $\beta$로 KL과 reconstruction의 균형을 조절하는 β-VAE(다음 절), decoder 출력을 discretization하는 VQ-VAE, 다른 가능도 함수를 쓰는 PixelCNN decoder, 또는 아예 다른 generative model 패러다임(GAN, diffusion)으로 옮겨가는 것 등이 있다.
Variational AutoEncoder
VAE는 잠재 변수 생성 모델 $p_\theta(x, z) = p(z)\, p_\theta(x \mid z)$를 maximum likelihood로 학습하는 방법이다. 학습 목표인 marginal log likelihood $\log p_\theta(x)$가 intractable하므로, 그 하한인 ELBO를 대신 최대화한다. ELBO의 gradient를 mini-batch SGD로 추정하는 estimator가 SGVB이고, SGVB에 amortized recognition network를 결합한 학습 절차가 AEVB이다. VAE는 AEVB에서 prior·posterior·decoder를 특정 분포로 고정한 경우에 해당한다. 본 장은 AEVB를 먼저 정의한 뒤 VAE를 그 사례로 유도한다.
4.0 배경과 이 장의 구성
Helmholtz Machine 절에서 두 가지가 확립되었다. 첫째, generative model $p_\theta(x, z)$와 recognition model $q_\phi(z \mid x)$를 한 쌍으로 둔다. 둘째, intractable한 $\log p_\theta(x)$를 직접 최대화하는 대신 그 하한을 최대화한다. 그 하한은 variational free energy의 음수 $-\mathcal{F}$이며, ELBO라 부른다.
그러나 Helmholtz Machine의 학습 알고리즘인 wake-sleep은 하나의 목적함수를 최적화하지 않는다. 이유는 두 가지이다. 첫째, $z \sim q_\phi(z \mid x)$의 샘플링이 $\phi$에 대해 미분 불가능하여 gradient가 $\phi$로 전달되지 않는다. 둘째, sleep phase가 감소시키는 양은 ELBO에 포함된 $D_{\text{KL}}(q_\phi(z \mid x) \,\|\, p_\theta(z \mid x))$가 아니라 인자 순서가 반대인 $D_{\text{KL}}(p_\theta(z \mid x) \,\|\, q_\phi(z \mid x))$이며, 그것도 모델이 생성한 표본 위에서 평가된다. 따라서 wake-sleep의 두 갱신은 하나의 함수에 대한 좌표별 하강이 아니고, 수렴이 보장되지 않는다.
Kingma와 Welling [13]은 목적함수를 바꾸지 않고 ELBO gradient의 추정 방법을 제시했다. 이 추정량을 SGVB(Stochastic Gradient Variational Bayes)라 하고, SGVB에 amortized recognition network와 mini-batch SGD를 결합한 학습 알고리즘을 AEVB(Auto-Encoding Variational Bayes)라 한다.
AEVB의 의의는 학습 절차의 통합에 있다. wake-sleep은 wake/sleep 두 phase로, EM은 E-step과 M-step으로 모수를 교대 갱신한다. AEVB는 이러한 교대 없이 $\theta$와 $\phi$를 단일 목적함수 ELBO에 대한 하나의 SGD로 동시에 갱신한다.
VAE는 AEVB에서 prior, posterior, decoder를 다음과 같이 고정한 경우이다. prior는 $p(z) = \mathcal{N}(0, I)$, posterior는 대각 Gaussian, encoder와 decoder는 MLP이다. 본 장은 다음 순서로 전개한다. 일반 문제 설정과 ELBO(4.1), gradient 추정의 어려움과 그 해결(4.2–4.3), AEVB 알고리즘(4.4)을 정의한 뒤, VAE를 그 사례로 구체화하고(4.5), 학습된 VAE의 성질을 정리한다(4.6).
| 층위 | 무엇인가 | 이 장에서 새로 더해지는 것 |
|---|---|---|
| 문제 | $\max_\theta \log p_\theta(x)$. 그러나 marginal과 posterior가 모두 intractable, 게다가 대규모 데이터 | (이미 정의됨) SGD로 풀 수 있어야 한다는 요구 |
| ELBO | $\log p_\theta(x)$의 다룰 수 있는 하한. reconstruction 항 $-$ KL 항 | (Helmholtz의 $-\mathcal{F}$와 같은 양) VAE 표기로 재유도(4.1) |
| SGVB | reparameterization에 기반한 ELBO의 저분산 gradient estimator | 샘플링을 $\phi$ 밖으로 빼내 gradient가 흐르게 함(4.3) |
| AEVB | SGVB + amortized recognition network + 미니배치 SGD | 전 데이터에 단일 목적함수로 동시 학습(4.4) |
| VAE | AEVB의 한 특수 사례 | $p(z) = \mathcal{N}(0, I)$, 대각 Gaussian $q_\phi$, MLP, exp-family decoder(4.5) |
앞 장에서 정리한 AutoEncoder의 세 한계, 즉 latent에 명시적 prior가 없음, encoder가 입력을 한 점으로 사상함, 확률 모델이 아님은 비선형 층을 쌓은 deep AutoEncoder에서도 유지된다. 표현력의 증가만으로는 generative model이 되지 않는다. VAE가 추가하는 것은 깊이가 아니라 확률 구조이며, SGVB/AEVB는 그 확률 구조를 mini-batch SGD로 학습 가능하게 만든다.
이 framework의 후속 영향은 주로 generative model에 나타난다. VQ-VAE는 이 구조를 이미지 토크나이저로 확장하여 DALL-E 계열로 이어지고, latent diffusion은 VAE가 학습한 latent space 위에서 동작하여 Stable Diffusion으로 이어진다(6장). 또한 reparameterization과 amortized inference는 변분·확률 모델 학습의 표준 도구가 되었다.
4.1 일반 문제 설정과 ELBO
4.1.1 generative model과 intractable한 두 양
이 절의 문제는 모수적 모델의 maximum likelihood 추정이다. 고정된 미지 모수 $\theta$를 데이터로부터 한 값으로 정하는 점 추정이며, 기준은 likelihood이다. 표준적인 점 추정과 다른 점은 모델이 잠재 변수를 포함한다는 것이며, 이로부터 성격이 다른 두 추정 문제가 분리되어 나온다. 본 절은 그 둘을 구분하고, 각각을 막는 양을 식별한다.
잠재 변수 생성 모델을 다음과 같이 둔다. 잠재 변수 $z$는 연속이고, joint density는 prior와 conditional의 곱으로 분해된다.
이 분해는 임의의 joint density에 성립하는 항등식이며, 모델 가정은 $p(z)$와 $p_\theta(x \mid z)$의 구체적 형태에서 들어온다. 그 형태는 4.5에서 정한다. 한편 이 식은 생성 과정을 그대로 나타낸다. 먼저 $z \sim p(z)$를 추출하고, 이어서 $x \sim p_\theta(x \mid z)$를 추출한다.
학습은 데이터 $\{x_1, \ldots, x_N\}$에 대한 marginal log likelihood의 최대화이다. 아래 양을 모수 $\theta$에 대한 likelihood로 보고 그 log를 최대화하는 maximum likelihood 점 추정이다.
합 형태 $\sum_i \log p_\theta(x_i)$와 기댓값 형태 $N \cdot \mathbb{E}_{x \sim p_D}[\log p_\theta(x)]$는 같은 양이다($p_D$는 경험적 분포, 정의는 아래). 잠재 변수 모델이라는 점에서 추정 문제가 두 가지로 갈린다.
첫째는 모수 $\theta$의 추정이다. $\theta$는 고정된 미지수이므로 위 likelihood를 최대화하여 한 값으로 점 추정한다. 둘째는 잠재 변수의 추정이다. 잠재 변수는 데이터마다 하나씩 $z_1, \ldots, z_N$으로 존재하며, 이들은 모수가 아니라 확률변수이다. 확률변수의 점 추정은 Bayes estimator, 즉 posterior $p_\theta(z \mid x)$의 평균이나 최빈값이다(squared loss이면 posterior mean, 0–1 loss이면 posterior mode).
잠재 변수 $z_i$는 데이터 한 점마다 하나씩 있으므로 데이터가 늘면 그 수도 함께 늘어난다. 따라서 $z_i$ 하나하나를 추정 대상으로 두는 대신, prior $p(z)$를 부여해 적분으로 소거한다. 그러면 실제로 추정하는 모수는 데이터 수와 무관하게 $\theta$ 하나로 고정된다. marginal $p_\theta(x) = \int p_\theta(x \mid z)\, p(z)\, dz$의 적분이 이 소거에 해당한다.
또한 모델은 각 $x$가 저차원 $z$에서 생성된다고 가정한다. 따라서 $z$를 복원하는 일은 고차원 $x$를 저차원 좌표로 줄이는 data reduction이며, 이후 recognition model이 그 reduction을 담당한다. 다만 이 $z$는 $x$의 정보를 모두 보존하는 요약은 아니며, 손실 있는 압축이다.
두 추정 문제는 각각 계산 불가능한 양에 막힌다.
- marginal likelihood $p_\theta(x) = \int p_\theta(x \mid z)\, p(z)\, dz$: $\theta$의 점 추정 대상이다. $z$가 고차원이고 $p_\theta(x \mid z)$가 비선형 neural network이므로 적분의 closed form이 없으며, 수치 적분의 비용은 차원에 대해 지수적으로 증가한다. 표본 평균 $\frac{1}{S}\sum_s p_\theta(x \mid z^{(s)})$, $z^{(s)} \sim p(z)$는 unbiased이나, $p(z)$에서 추출한 대부분의 $z$에서 $p_\theta(x \mid z)$가 작아 추정량의 variance가 크다.
- posterior $p_\theta(z \mid x) = p_\theta(x \mid z)\, p(z) / p_\theta(x)$: $z$의 Bayes 추정에 필요하다. 분모가 위 marginal이므로 역시 계산할 수 없다.
또한 데이터 수 $N$이 크다고 가정한다. 따라서 전 데이터에 대한 batch 최적화나 데이터마다 별도의 추론을 수행하는 절차는 비용이 크고, mini-batch SGD로 최적화 가능한 형태가 요구된다.
4.1.2 변분 근사와 amortized inference
intractable한 posterior에 대한 표준적 접근은 approximate inference이며 두 부류가 있다. MCMC는 posterior에서 표본을 추출하여 근사한다. 점근적으로 정확하나 데이터마다 Markov chain을 실행하므로 비용이 크다. Variational inference(VI)는 다루기 쉬운 분포족 $\mathcal{Q}$ 안에서 posterior에 가장 가까운 분포를 선택한다. 계산은 빠르나, $\mathcal{Q}$가 진짜 posterior를 포함하지 않으면 근사 오차가 남는다. VAE는 VI를 사용한다.
전통적 VI는 데이터 $x_i$마다 별도의 variational parameter $\phi_i$를 최적화하므로, 데이터 수 $N$에 비례하는 최적화 문제를 푼다. 대신 사상 $x \mapsto q(z \mid x)$를 neural network $f_\phi$로 두어 모든 데이터가 모수 $\phi$를 공유하게 한다. 이를 amortized inference라 한다(AEVB의 "auto-encoding"이 이 amortization을 가리킨다). 학습 후 새 $x$에 대한 근사 posterior는 $f_\phi$의 한 번의 forward로 얻는다.
$f_\phi$를 recognition network 또는 encoder라 하며, 입력 $x$로부터 잠재 분포의 모수를 출력한다. 식 (21.6)의 $\approx$는 다음을 뜻한다. 진짜 posterior가 계산 불가능하므로, 분포족 $\mathcal{Q}$ 안에서 그것에 KL divergence로 가장 가까운 분포를 택한다. 이 KL을 최소화하는 것은 다음 절에서 유도하는 ELBO를 최대화하는 것과 동치이다(4.1.3).
4.1.3 ELBO 유도
intractable한 $\log p_\theta(x)$의 하한을 유도한다. 사용하는 도구는 Jensen 부등식이다.
$\varphi : \mathbb{R} \to \mathbb{R}$가 concave function이고 $X$가 integral 가능한 random variable이면,
$$\varphi\!\big(\mathbb{E}[X]\big) \;\geq\; \mathbb{E}\!\big[\varphi(X)\big]$$이 성립한다. $\log$는 strictly concave이므로 등호는 $X$가 상수일 때만 성립한다.
$\log$는 $(0, \infty)$에서 concave이므로 $\log \mathbb{E}[X] \geq \mathbb{E}[\log X]$가 성립한다.
임의의 분포 $q_\phi(z \mid x)$에 대해 부등식을 다음과 같이 적용한다. 이 결과는 Helmholtz Machine 절의 free energy 유도와 동일하며, 여기서는 VAE 표기로 다시 전개한다.
두 번째 줄은 분자와 분모에 $q_\phi(z \mid x)$를 곱한 항등 변형이고($q_\phi$가 0이 아닌 영역에서 정의됨), 세 번째 줄은 expectation의 정의, 네 번째 줄은 보조정리 4.1의 적용이다. 다섯째·여섯째 줄은 joint density의 chain rule 분해이다. 마지막 줄에서 $\log$의 분자가 $p(z)$, 분모가 $q_\phi(z \mid x)$이므로, 부호를 반대로 하여 KL로 정리한다.
KL의 정의 $D_{\text{KL}}(q \| p) = \mathbb{E}_q[\log(q/p)]$에서 분자·분모의 순서가 위 식과 반대이므로 부호가 바뀐다.
마지막 줄을 Evidence Lower BOund (ELBO)라 한다.
두 항. 첫째 항 $\mathbb{E}_{q_\phi}[\log p_\theta(x \mid z)]$는 $q_\phi$에서 추출한 $z$에 대한 $x$의 평균 log likelihood이며, reconstruction 항이라 한다. 둘째 항 $D_{\text{KL}}(q_\phi(z \mid x) \,\|\, p(z))$는 근사 posterior와 prior의 KL이다. 두 항의 최적 방향은 상충한다. 첫째 항은 입력마다 서로 다른 $z$ 분포를 요구하고, 둘째 항은 모든 입력의 $z$ 분포를 prior에 일치시키려 한다. (둘째 항은 정보이론에서 잠재 코드가 입력에 대해 담는 정보량으로 해석되며, 5장 β-VAE의 rate에 해당한다.)
하한과 등호 조건. Jensen의 등호 조건에 의해, ELBO가 $\log p_\theta(x)$와 같아지는 것은 $p_\theta(x, z) / q_\phi(z \mid x)$가 $z$에 무관한 상수일 때, 즉 $q_\phi(z \mid x) = p_\theta(z \mid x)$일 때이다. 이는 다음 항등식으로도 확인된다. $\log p_\theta(x)$가 $z$에 대해 상수임을 이용하여 부등식의 간격을 정리하면
즉 ELBO와 $\log p_\theta(x)$의 차이는 근사 posterior와 진짜 posterior 사이의 KL이다. 이 KL이 0 이상이므로 ELBO는 하한이고, KL이 0일 때, 즉 $q_\phi(z \mid x) = p_\theta(z \mid x)$일 때 등호가 성립한다. 또한 ELBO를 $\theta$에 대해 최대화하면 $\log p_\theta(x)$가 증가하고, $\phi$에 대해 최대화하면 이 KL이 감소하여 근사 posterior가 진짜 posterior에 가까워진다. 두 목표가 하나의 목적함수에 포함되어 동시에 최적화된다.
4.2 gradient 추정의 어려움
ELBO를 gradient로 최대화할 때 $\theta$와 $\phi$에 대한 gradient의 성격이 다르다. 차이는 기댓값을 정의하는 분포 $q_\phi$가 어느 모수에 의존하는가에서 나온다.
$\theta$의 경우, $q_\phi$가 $\theta$에 의존하지 않으므로 미분과 기댓값의 순서를 바꿀 수 있다.
우변은 $z \sim q_\phi(z \mid x)$를 추출하여 $\nabla_\theta \log p_\theta(x \mid z)$를 평균하면 unbiased로 추정된다. 미분이 적분 대상 $\log p_\theta(x \mid z)$에만 작용하고, 이 함수는 $z$가 주어지면 $\theta$에 대해 미분 가능하기 때문이다.
$\phi$의 경우, $q_\phi$가 $\phi$에 의존하므로 같은 교환이 성립하지 않는다. reconstruction 항을 적분으로 쓰고 미분하면 다음과 같다.
적분 대상 $\log p_\theta(x \mid z)$는 $\phi$를 포함하지 않으므로 미분은 density $q_\phi$에만 작용한다. 그런데 $\nabla_\phi q_\phi$는 분포가 아니다. $\int \nabla_\phi q_\phi(z \mid x)\, dz = \nabla_\phi \!\int q_\phi(z \mid x)\, dz = \nabla_\phi 1 = 0$이고, 값의 부호도 일정하지 않다. 따라서 우변은 $\mathbb{E}_{q_\phi}[\,\cdot\,]$의 형태가 아니며, $z \sim q_\phi$를 추출하여 함숫값을 평균하는 방식으로는 추정되지 않는다. 이것이 $\theta$와의 차이이다. $\theta$에서는 미분이 적분 대상에 떨어져 곧바로 기댓값이 되지만, $\phi$에서는 미분이 density에 떨어진다.
계산 그래프의 관점에서 같은 사실은 다음과 같다. $\phi$의 영향은 적분 대상이 아니라 $z$를 추출하는 분포에 들어 있다. 그러나 표본 $z \sim q_\phi(z \mid x)$가 한 번 추출되면 그 값에는 $\phi$가 남아 있지 않아 $\nabla_\phi \log p_\theta(x \mid z) = 0$이다. 즉 $\phi$에 대한 gradient는 추출된 $z$의 값이 아니라 추출 분포가 $\phi$에 따라 이동하는 데서 나오는데, 추출 연산 자체가 $\phi$에 대해 미분되지 않으므로 이 gradient가 encoder로 전달되지 않는다.
Score function estimator (REINFORCE). 장애는 $\nabla_\phi q_\phi$가 분포가 아니라는 데 있었다. 항등식 $\nabla_\phi q_\phi = q_\phi\, \nabla_\phi \log q_\phi$를 위 적분에 대입하면 우변이 다시 $q_\phi$에 대한 기댓값이 된다.
이제 우변은 $z \sim q_\phi$를 추출하여 추정할 수 있다(여기서 $f(z) = \log p_\theta(x \mid z)$이며, ELBO 전체에서는 $f$에 $-\log q_\phi$가 더해지나 그 추가 항의 기댓값은 $\mathbb{E}_q[\nabla_\phi(-\log q_\phi)] = -\nabla_\phi \int q_\phi\, dz = 0$이다). 이 추정량은 unbiased이고 $z$가 이산인 경우에도 적용된다. 그러나 $f(z)$ 전체에 score $\nabla_\phi \log q_\phi$가 곱해지므로 추정량의 variance가 크고, 학습 속도와 안정성이 떨어진다. 즉 $\phi$에 대한 gradient는 추정이 불가능한 것이 아니라, unbiased 추정량의 variance가 큰 것이 문제이다. 다음 절은 같은 gradient를 더 낮은 variance로 추정하는 방법을 다룬다. 그 방법은 추출의 무작위성을 $\phi$와 무관한 noise로 옮겨, $\phi$를 다시 적분 대상으로 되돌린다.
4.3 Reparameterization과 SGVB estimator
variance를 줄이는 방법은 $q_\phi$의 무작위성을 $\phi$와 무관한 분포로 옮기는 것이다. $z \sim q_\phi(z \mid x)$를 다음 두 단계로 표현한다.
- $\phi$와 무관한 고정 분포에서 noise를 추출한다: $\epsilon \sim p(\epsilon)$.
- 결정론적이고 미분 가능한 변환으로 $z$를 정의한다: $z = g_\phi(\epsilon, x)$.
단계 2에서 $z$가 $\epsilon$의 결정론적 함수로 정의되므로, $z$의 분포는 $\epsilon$의 분포 $p(\epsilon)$로부터 정해진다. $g_\phi$는 $\epsilon \sim p(\epsilon)$를 통과시킨 $z$의 분포가 정확히 $q_\phi(z \mid x)$가 되도록 잡는다(Gaussian의 경우 4.5.2에서 구성한다). 그러면 임의의 함수 $f$에 대해 같은 기댓값을 두 가지 방식으로 적을 수 있다.
좌변은 $z$의 분포로, 우변은 $\epsilon$의 분포로 적은 같은 기댓값이다. $z = g_\phi(\epsilon, x)$가 $\epsilon$의 함수이므로 $f(z)$의 기댓값은 $f(g_\phi(\epsilon, x))$의 기댓값과 같다. $q_\phi$의 명시적 형태나 변환의 Jacobian은 이 등식에 필요하지 않다.
이제 양변에 $\nabla_\phi$를 취한다. 우변의 기댓값을 정의하는 분포 $p(\epsilon)$가 $\phi$에 의존하지 않으므로, 4.2의 $\theta$ 경우와 같은 이유로 미분과 기댓값의 순서를 바꿀 수 있다. 이어서 합성함수 $f(g_\phi(\epsilon, x))$에 chain rule을 적용한다.
마지막 식의 두 인수는 모두 계산 가능한 양이다. $\nabla_z f(z) = \nabla_z \log p_\theta(x \mid z)$는 decoder를 통과한 미분이고, $\partial g_\phi / \partial \phi$는 결정론적 함수 $g_\phi$를 $\phi$로 미분한 것이다. 둘 다 결정론적 계산 그래프 위에서 backpropagation으로 얻는다.
4.2와 비교하면 두 가지가 달라졌다. 첫째, $\phi$가 더 이상 표본을 추출하는 분포 안에 있지 않다. 추출은 $\phi$와 무관한 $\epsilon \sim p(\epsilon)$에서 한 번 일어나고, $\phi$의 영향은 그 뒤의 미분 가능한 함수 $g_\phi$로 들어간다. 따라서 4.2에서 막혔던 지점, 즉 추출 연산이 $\phi$에 대해 미분되지 않는다는 점이 사라지고, chain rule이 $g_\phi$를 통해 encoder까지 이어진다. 둘째, gradient의 형태가 score function estimator와 다르다. score function은 $f(z)\, \nabla_\phi \log q_\phi(z \mid x)$로 함숫값 $f(z)$ 전체에 score를 곱했다. 여기서는 $\nabla_z f \cdot (\partial g_\phi / \partial \phi)$로, $f$의 값이 아니라 $f$의 도함수가 곱해진다. $z$를 조금 움직였을 때 $f$가 어떻게 변하는지를 직접 사용하므로 추정량의 variance가 작다.
따라서 $\epsilon \sim p(\epsilon)$를 추출하여 위 피적분 함수를 계산하면 $\nabla_\phi \mathbb{E}_{q_\phi}[f]$의 unbiased 추정이 된다. 예를 들어 Gaussian posterior $\mathcal{N}(\mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x)))$에서는 $\epsilon \sim \mathcal{N}(0, I)$, $g_\phi(\epsilon, x) = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon$이고, $\partial z / \partial \mu = 1$, $\partial z / \partial \sigma = \epsilon$으로 모두 미분 가능하다(이 형태의 유도는 4.5.2). $g_\phi$의 구체적 형태는 분포에 따라 다르다.
reparameterization으로 ELBO를 추정한 양을 SGVB estimator라 한다. 두 가지 형태가 있다.
$\tilde{\mathcal{L}}^A$는 ELBO 전체를 표본 평균으로 추정한다. $\tilde{\mathcal{L}}^B$는 KL 항을 closed form으로 계산하고 reconstruction 항만 표본 평균으로 추정한다. 두 추정량 모두 ELBO의 unbiased 추정이며, $\tilde{\mathcal{L}}^B$는 KL 항을 추정하지 않으므로 variance가 더 작다. 다만 $\tilde{\mathcal{L}}^B$는 $D_{\text{KL}}(q_\phi(z \mid x) \,\|\, p(z))$의 closed form을 요구한다. VAE가 prior와 posterior를 Gaussian으로 두는 이유가 이것이며, 해당 closed form은 4.5.3에서 유도한다.
mini-batch 크기가 충분히 크면 표본 수 $L = 1$로도 학습이 안정적이며, 이 경우에도 추정량은 unbiased이다.
4.4 AEVB 알고리즘
SGVB estimator, amortized recognition network, mini-batch SGD를 결합하면 학습 알고리즘이 정의된다. 이를 AEVB라 한다. 크기 $M$의 mini-batch $X^M = \{x^{(1)}, \ldots, x^{(M)}\}$에 대한 목적함수는 전체 데이터 규모로 스케일한 값이다.
출력: 학습된 $\theta$ (generative), $\phi$ (recognition)
2: repeat
3: 미니배치 $X^M \sim p_D$ // 데이터셋에서 $M$개
4: 각 $x^{(i)}$에 대해 $\epsilon^{(i)} \sim p(\epsilon)$ // 외부 noise
5: $z^{(i)} \leftarrow g_\phi\big(\epsilon^{(i)}, x^{(i)}\big)$ // reparameterization
6: $\tilde{\mathcal{L}}^M \leftarrow \tfrac{N}{M}\sum_i \tilde{\mathcal{L}}(\phi,\theta; x^{(i)})$ // SGVB ($\tilde{\mathcal{L}}^A$ 또는 $\tilde{\mathcal{L}}^B$)
7: $(\theta, \phi) \leftarrow (\theta, \phi) + \eta\, \nabla_{\theta, \phi}\, \tilde{\mathcal{L}}^M$ // SGD/Adam
8: until 수렴
이 알고리즘은 특정 분포에 의존하지 않는다. 사후 근사 $q_\phi$가 reparameterizable하고 $\log p_\theta(x \mid z)$를 평가할 수 있으면, prior와 decoder의 분포와 무관하게 동일하게 적용된다. 이 세 분포를 구체적으로 정한 경우가 VAE이며, 다음 절에서 다룬다.
4.5 예제: Variational Auto-Encoder
AEVB에서 prior $p(z)$, 사후 근사 $q_\phi(z \mid x)$, decoder $p_\theta(x \mid z)$를 구체적으로 정한 경우가 VAE이다. 본 절에서 세 분포를 정의하고, 4.4의 알고리즘을 이 경우로 특수화한다.
4.5.1 모델링 선택
Prior. prior는 standard Gaussian으로 둔다.
$d$는 잠재 차원이다. covariance가 대각이므로 각 좌표는 독립인 1차원 standard Gaussian을 따른다. standard Gaussian을 택하는 이유는 세 가지이다. (i) 학습 모수가 없다. (ii) posterior도 Gaussian이면 KL 항이 closed form이고(4.5.3), 따라서 $\tilde{\mathcal{L}}^B$를 사용할 수 있다. (iii) reparameterization $z = \mu + \sigma \odot \epsilon$이 명제 4.1로부터 직접 성립한다(4.5.2).
Posterior. 사후 근사는 대각 Gaussian으로 둔다.
encoder $f_\phi$는 $\mu_\phi(x)$와 $\sigma_\phi^2(x) \in \mathbb{R}^d$를 출력한다. variance의 양수성을 보장하기 위해 보통 $\log \sigma^2$를 출력한 뒤 $\exp$를 적용한다. covariance를 대각으로 두는 가정을 mean-field approximation이라 하며, 잠재 좌표들이 $x$ 조건부로 독립임을 뜻한다. 진짜 posterior는 좌표 간 상관을 가질 수 있으나, 계산 가능성을 위해 이 가정을 둔다.
Decoder. decoder $p_\theta(x \mid z)$의 형태는 다음 관찰에서 정해진다. AutoEncoder의 결정론적 함수 $\hat{x} = g_\theta(z)$를 그대로 조건부 분포로 쓰면 $p_\theta(x \mid z) = \delta(x - g_\theta(z))$이다. 이때 $\log p_\theta(x \mid z)$는 $x = g_\theta(z)$에서 발산하고 그 외에서 $-\infty$이므로, $g_\theta(z)$에 대한 gradient가 정의되지 않는다.
따라서 decoder가 $x$를 직접 출력하는 대신 $x$의 분포의 모수를 출력하도록 둔다.
neural network $g_\theta$는 결정론적이지만, $\eta$는 $x$가 아니라 분포의 모수이고 $x$는 그 분포를 따른다. 이때 $\log p_\theta(x \mid z)$가 유한하므로 gradient가 정의된다. 위 곱은 $x$의 좌표가 $z$ 조건부로 독립임을 가정한다. 분포로는 데이터 타입에 맞는 exponential family를 사용하며, 이는 2.2의 Gaussian decoder(MSE)와 Bernoulli decoder(BCE)를 포함한다.
| 데이터 타입 | 분포 | decoder 마지막 activation | 손실 함수 |
|---|---|---|---|
| 이진 $\{0, 1\}$ | Bernoulli | sigmoid (또는 logit 출력) | BCE |
| 연속 실수 | Gaussian | 없음 (linear) | MSE |
| 범주형 ($K$개 클래스) | categorical | softmax | cross-entropy |
| 카운트 | Poisson | $\exp$ | Poisson NLL |
네 경우 모두 구조가 같다. decoder가 natural parameter를 출력하고, exponential family 분포가 정의되며, negative log likelihood가 손실이 된다. Dirac delta는 exponential family에 속하지 않는 degenerate 분포이므로 이 구조에 포함되지 않는다.
두 모델 모두 decoder neural network 자체는 deterministic이다. 같은 $z$에 같은 출력이 나온다. 차이는 그 출력을 어떻게 해석하느냐에 있다. AE는 출력을 $x$ 자체로 보고, VAE는 출력을 $x$의 분포의 파라미터로 본다.
이상의 선택으로 정의된 VAE의 generative 방향과 inference 방향을 그림으로 나타내면 다음과 같다.
4.5.2 Gaussian의 affine 변환: $g_\phi$의 구체화
4.3에서 Gaussian posterior의 변환을 $g_\phi(\epsilon, x) = \mu + \sigma \odot \epsilon$로 적었다. 이때 $\epsilon \sim \mathcal{N}(0, I)$를 이 식에 통과시킨 $z$가 정말 $\mathcal{N}(\mu, \operatorname{diag}(\sigma^2))$의 표본인지 확인이 필요하다. 다음 명제가 그것을 보장한다. Gaussian의 affine 변환은 다시 Gaussian이며, 모수는 변환에 따라 정해진다.
random variable $\epsilon$이 다변량 Gaussian $\mathcal{N}(m, S)$를 따르고, 상수 행렬 $A$와 벡터 $b$에 대해 $z = A\epsilon + b$로 정의하면, $z$ 또한 Gaussian을 따르며 그 모수는 다음과 같다.
$$z \sim \mathcal{N}\!\big(Am + b,\; A S A^\top\big)$$mean은 선형성으로부터 $\mathbb{E}[z] = A\mathbb{E}[\epsilon] + b = Am + b$가 곧장 따라온다. covariance는 정의를 그대로 전개한다.
\begin{aligned} \operatorname{Cov}(z) &= \mathbb{E}\!\left[(z - \mathbb{E}[z])(z - \mathbb{E}[z])^\top\right] \\[4pt] &= \mathbb{E}\!\left[A(\epsilon - m)\,\big(A(\epsilon - m)\big)^\top\right] \\[4pt] &= \mathbb{E}\!\left[A(\epsilon - m)(\epsilon - m)^\top A^\top\right] \\[4pt] &= A\,\mathbb{E}\!\left[(\epsilon - m)(\epsilon - m)^\top\right]\,A^\top \\[4pt] &= A\,S\,A^\top \end{aligned}둘째 줄에서 $z - \mathbb{E}[z] = A(\epsilon - m)$을 대입했고, 셋째 줄에서 $(AB)^\top = B^\top A^\top$을, 넷째 줄에서 $A, A^\top$이 상수임을 썼다. (Gaussian성의 보존은 모멘트 생성 함수로 따로 확인된다.)
이를 VAE에 적용한다. 목표는 $\epsilon \sim \mathcal{N}(0, I)$로부터 posterior $\mathcal{N}(\mu, \operatorname{diag}(\sigma^2))$의 표본을 만드는 변환 $z = A\epsilon + b$를 찾는 것이다. $m = 0$, $S = I$이므로 명제 4.1에 의해 $z \sim \mathcal{N}(b,\, A A^\top)$이다. 이 분포가 목표 분포와 같으려면 mean과 covariance가 각각 일치해야 한다.
첫 조건에서 $b = \mu$이다. 둘째 조건 $A A^\top = \operatorname{diag}(\sigma^2)$는 $A = \operatorname{diag}(\sigma)$로 만족된다($\operatorname{diag}(\sigma)\,\operatorname{diag}(\sigma)^\top = \operatorname{diag}(\sigma^2)$). 두 값을 대입하면 변환이 정해진다.
이것이 4.3에서 적은 $g_\phi(\epsilon, x) = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon$이다. 즉 그 변환은 임의로 고른 것이 아니라, posterior를 $\mathcal{N}(\mu, \operatorname{diag}(\sigma^2))$로 두었을 때 명제 4.1로부터 따라 나온 결과이다(viz 09 오른쪽). full covariance $\Sigma$를 쓰려면 조건이 $A A^\top = \Sigma$가 되고, 이를 만족하는 하삼각 행렬 $A$로 같은 방식이 성립한다(4.5.4 sidenote).
4.5.3 Gaussian KL의 닫힌 형태
$\tilde{\mathcal{L}}^B$는 KL 항의 closed form을 요구한다(4.3). prior와 posterior가 모두 Gaussian이면 이 KL이 closed form으로 주어진다. $q_\phi(z \mid x) = \mathcal{N}(\mu, \operatorname{diag}(\sigma^2))$, $p(z) = \mathcal{N}(0, I)$이고 둘 다 $d$차원일 때 다음이 성립한다.
KL의 정의와, 두 분포가 모두 대각 covariance라 각 차원이 독립이라는 점에서 차원별 합으로 분해된다.
$$D_{\text{KL}}(q \,\|\, p) = \mathbb{E}_q[\log q(z) - \log p(z)] = \sum_{j=1}^{d} D_{\text{KL}}\!\big(\mathcal{N}(\mu_j, \sigma_j^2) \,\|\, \mathcal{N}(0, 1)\big)$$1차원 Gaussian의 로그 밀도 $\log \mathcal{N}(z \mid \mu, \sigma^2) = -\tfrac{1}{2}\log(2\pi\sigma^2) - \frac{(z-\mu)^2}{2\sigma^2}$를 대입하면
\begin{aligned} D_{\text{KL}}\!\big(\mathcal{N}(\mu, \sigma^2) \,\|\, \mathcal{N}(0, 1)\big) &= \mathbb{E}_{q}\!\left[-\tfrac{1}{2}\log(2\pi\sigma^2) - \frac{(z-\mu)^2}{2\sigma^2} + \tfrac{1}{2}\log(2\pi) + \frac{z^2}{2}\right] \\[4pt] &= -\tfrac{1}{2}\log \sigma^2 - \mathbb{E}_q\!\left[\frac{(z-\mu)^2}{2\sigma^2}\right] + \mathbb{E}_q\!\left[\frac{z^2}{2}\right] \end{aligned}($\log(2\pi)$ 항이 상쇄된다.) 이제 $\mathbb{E}_q[(z-\mu)^2] = \sigma^2$로부터 $\mathbb{E}_q[(z-\mu)^2/2\sigma^2] = \tfrac{1}{2}$이고, $\mathbb{E}_q[z^2] = \sigma^2 + \mu^2$로부터 $\mathbb{E}_q[z^2/2] = (\sigma^2 + \mu^2)/2$이므로
$$D_{\text{KL}} = -\tfrac{1}{2}\log \sigma^2 - \tfrac{1}{2} + \frac{\sigma^2 + \mu^2}{2} = \tfrac{1}{2}\big(\mu^2 + \sigma^2 - \log \sigma^2 - 1\big)$$차원별 합을 취하면 본문 식이다.
각 항의 의미는 다음과 같다. $\mu_j^2$는 mean이 prior의 중심 0에서 벗어난 정도에 대한 항이고, $\sigma_j^2 - \log \sigma_j^2 - 1$은 $\sigma_j^2 = 1$에서 최솟값 0을 갖는 convex 함수이므로 variance가 1에서 벗어나면 양방향으로 증가한다. KL이 0이 되는 조건은 $\mu_j = 0$, $\sigma_j^2 = 1$이며, 이 경우 모든 입력이 같은 분포로 사상되어 reconstruction이 불가능하다. 따라서 학습 중 KL은 양의 값에서 reconstruction 항과 균형을 이룬다. 이 closed form은 좌표별로 분리되어 미분 가능하다.
4.5.4 VAE 학습 알고리즘
4.4의 알고리즘 4.1을 위 분포 선택으로 특수화하면 다음이 된다. 데이터 한 점 $x$ 기준으로 적으며, 실제로는 mini-batch 위에서 평균을 취한다.
출력: 학습된 $\theta$ (decoder), $\phi$ (encoder)
2: repeat
3: $x \sim p_D$ // 데이터셋에서 한 점
4: $\epsilon \sim \mathcal{N}(0, I)$ // 외부 noise
5: $(\mu, \log \sigma) \leftarrow f_\phi(x)$ // encoder forward
6: $\sigma \leftarrow \exp(\log \sigma)$
7: $z \leftarrow \mu + \sigma \odot \epsilon$ // reparameterization (명제 4.1 = $g_\phi$)
8: $\eta_x \leftarrow g_\theta(z)$ // decoder forward, natural parameter
9: $\log q_\phi(z\mid x) \leftarrow -\sum_{k=1}^{d} \!\left[\tfrac{1}{2}\epsilon_k^2 + \tfrac{1}{2}\log(2\pi) + \log \sigma_k\right]$
10: $\log p(z) \leftarrow -\sum_{k=1}^{d} \!\left[\tfrac{1}{2} z_k^2 + \tfrac{1}{2}\log(2\pi)\right]$
11: $\log p_\theta(x\mid z) \leftarrow$ (Gaussian이면 MSE 형태, Bernoulli면 BCE 형태)
12: $\mathcal{L} \leftarrow \log p_\theta(x\mid z) + \log p(z) - \log q_\phi(z\mid x)$ // SGVB $\tilde{\mathcal{L}}^A$, $L{=}1$
13: $(\theta, \phi) \leftarrow (\theta, \phi) + \eta\, \nabla_{\theta, \phi} \mathcal{L}$
14: until 수렴
각 줄의 근거는 다음과 같다. Line 3은 4.1.1의 경험적 분포에서 한 점을 추출한다. Line 4, 7은 4.3의 reparameterization을 명제 4.1로 구체화한 것이다. Line 5는 $\sigma > 0$을 보장하기 위해 $\log \sigma$를 출력한다. Line 8의 $\eta_x$는 4.5.1의 natural parameter이다.
Line 9 ($\log q_\phi$의 닫힌 형태). 대각 covariance $\Sigma = \operatorname{diag}(\sigma^2)$이면 $|\Sigma| = \prod_k \sigma_k^2$, $\Sigma^{-1} = \operatorname{diag}(1/\sigma^2)$이므로
reparameterization에 의해 $z_k - \mu_k = \sigma_k \epsilon_k$이므로 $(z_k - \mu_k)^2/\sigma_k^2 = \epsilon_k^2$이고, $\log \sigma_k^2 = 2\log\sigma_k$이므로 알고리즘의 식이 나온다. 결과가 $z$ 없이 $\epsilon$과 $\sigma$만으로 표현된다.
Line 10 ($\log p(z)$의 닫힌 형태). $p(z) = \mathcal{N}(0,I)$이므로 $\log p(z) = -\tfrac{d}{2}\log(2\pi) - \tfrac{1}{2}\|z\|^2$이고 학습 파라미터가 없다. Line 11. 데이터 타입에 따라 2.2의 두 유도 중 하나(Gaussian → MSE, Bernoulli → BCE)가 들어간다.
Line 12. 위 의사코드는 $\tilde{\mathcal{L}}^A$(ELBO 전체를 단일 표본으로 추정)이다. 4.5.3의 closed form KL을 사용하면 $\tilde{\mathcal{L}}^B = -D_{\text{KL}} + \log p_\theta(x \mid z)$가 되며, KL을 정확히 계산하므로 variance가 더 작다. 두 형태 모두 ELBO를 추정한다. Line 13. ELBO는 최대화 대상이므로 gradient ascent이나, 실제로는 $-\mathcal{L}$을 손실로 정의하여 gradient descent로 최소화한다. 부호만 다르고 동치이다.
4.6 학습된 VAE의 성질
4.6.1 능력
학습된 VAE는 다음을 수행한다.
- reconstruction: 입력 $x$를 encoder로 압축(mean $\mu_\phi(x)$ 사용)한 뒤 decoder로 복원한다. AE와 같은 방식이다.
- 생성: prior $p(z) = \mathcal{N}(0, I)$에서 $z$를 뽑아 decoder에 통과시킨다. 학습 데이터에 없던 새 샘플이 만들어진다.
- latent space 보간: 두 입력의 인코딩 $z_1, z_2$ 사이를 $z_t = (1-t)z_1 + t z_2$로 보간해 디코딩하면 부드럽게 변하는 일련의 이미지를 얻는다.
- 잠재 산술: "안경 쓴 사람의 $z$ − 안경 없는 사람의 $z$ + 다른 사람의 $z$" 같은 연산이 의미를 가지는 경우가 있다.
VAE의 구조는 일반 AutoEncoder와 유사하나, 다음 점에서 다르다.
| 항목 | 일반 AE | VAE |
|---|---|---|
| encoder 출력 | 결정론적 벡터 $z$ | 확률 분포 $q_\phi(z \mid x)$ |
| 학습 목표 | reconstruction 오차 최소화 | ELBO 최대화 (reconstruction 항 + KL 항) |
| latent space 구조 | 구조에 대한 보장 없음 | prior에 가깝게 정렬됨 |
| 새 샘플 생성 | 불가 | 가능 ($z \sim p(z)$를 뽑아 디코딩) |
| probabilistic model인가 | 아니다 (회귀 문제) | 그렇다 ($p_\theta(x)$를 학습) |
요약하면 VAE는 결정론적 AutoEncoder에 확률 구조와 KL 정규화를 더한 모델이다. AutoEncoder의 목표가 데이터를 복원하는 표현의 학습이라면, VAE의 목표는 데이터 분포 $p(x)$를 학습하여 새 표본을 생성하는 것이다.
4.6.2 알려진 약점: 흐릿한 샘플
VAE의 알려진 약점은 생성 표본이 흐릿하다는 것이다. GAN이나 diffusion model의 출력과 비교하면 세부가 부족하다. 이는 Gaussian decoder와 MSE 손실의 조합에서 따라 나온다.
Gaussian decoder의 negative log likelihood는 MSE에 비례한다. 하나의 잠재 코드 $z$에 여러 입력 $x$가 대응할 때, MSE를 최소화하는 decoder 출력은 그 입력들의 평균이다. 이미지의 평균은 세부가 상쇄되어 흐릿하게 나타난다.
이 약점에 대한 접근은 여러 가지이다. KL 가중치를 조절하는 β-VAE(5장), latent를 이산화하는 VQ-VAE(6장), 다른 likelihood를 쓰는 PixelCNN decoder, 또는 다른 모델군(GAN, diffusion)이 있다. 본 장의 framework 관점에서, β-VAE는 목적함수(ELBO의 KL 가중치)를 변경하고, VQ-VAE는 latent를 연속에서 이산으로 바꾸며 변분 추론 골격을 사용하지 않는다.
β-VAE
ELBO에 weight 하나를 더 붙인 변종이다. 그 한 글자가 모델의 성격을 바꿔 놓으며, 정보이론과 표현 학습의 두 개념인 Information information bottleneck, Rate-Distortion과 연결된다.
4.1 β-VAE의 정의
β-VAE [16]는 표준 VAE의 loss function에서 KL term 앞에 weight $\beta \geq 0$를 곱한 변종이다. $\beta = 1$이면 정확히 표준 VAE의 negative ELBO이지만, $\beta \neq 1$인 경우 이 양은 더 이상 어떤 $\log p_\theta(x)$의 lower bound도 아니라는 점에 유의한다.
$\beta \neq 1$인 경우에는 ELBO를 최대화한다는 해석이 성립하지 않으며, 따라서 $\log p_\theta(x)$의 lower bound라는 의미도 사라진다. 그러나 실용적으로 의미 있는 학습 objective이고, 뒤에서 보듯이 information theory 관점에서 깔끔한 해석이 따라온다.
2.2의 유도 1에서 Gaussian decoder의 negative log likelihood는 $\frac{1}{2\sigma^2}\|x - \hat{x}\|^2 + \text{const}$였다. ELBO 안에 이를 대입하면 reconstruction 항의 계수가 $\frac{1}{2\sigma^2}$이며 KL 항의 계수는 $1$이다.
$$\mathcal{L}_{\text{ELBO}} = -\frac{1}{2\sigma^2}\|x - \hat{x}\|^2 - D_{\text{KL}}(q_\phi \| p) + \text{const}$$곧 $\sigma^2$의 선택이 이미 reconstruction과 KL의 *상대적 weight*를 결정하고 있었던 셈이다. $\sigma^2$를 키우면 reconstruction 항이 약해지고 KL의 상대적 weight가 커지며, 이는 정확히 β-VAE에서 $\beta > 1$로 두는 효과와 같다. 곧 β는 임의로 도입된 새 hyperparameter가 아니라, 본 강의의 2장부터 사실상 *고정된 상수로 간주하고 있던 $\sigma^2$의 재조정*에 해당한다. β-VAE의 기여는 이 자유도를 *명시적 control parameter*로 끄집어낸 것이다.
4.2 β의 효과
β의 값에 따라 모델은 서로 다른 영역에서 동작한다.
| $\beta$ | 모델 성격 |
|---|---|
| $\beta = 0$ | KL term이 사라진다. Encoder가 분포의 mean과 variance를 출력하지만 어떤 regularization도 받지 않는다. Reconstruction loss만 보면 같은 $x$에 대해 매번 다른 $z$가 sampling된 것은 일관된 reconstruction에 불리하므로, optimization은 $\sigma \to 0$으로 가는 것을 선호하고 결국 AutoEncoder의 동작에 수렴한다. latent space 구조에 대한 제약이 사라진다. |
| $0 < \beta < 1$ | reconstruction이 우선시되는 영역이다. 이미지 복원은 더 선명해지지만 latent space의 정돈은 표준 VAE보다 약하다. |
| $\beta = 1$ | 표준 VAE. ELBO와 일치한다. |
| $\beta > 1$ | 정규화가 강해진다. latent space가 prior에 가까워지도록 더 세게 끌어당겨지며, reconstruction은 흐려지는 대신 disentangled representation의 경향성이 나타난다. |
$\beta = 0$이라 해도 표준 AutoEncoder와 완전히 같지는 않다. VAE의 encoder는 분포(mean과 variance)를 출력하고 forward 때마다 $z$를 새로 뽑기 때문에, variance가 정확히 0이 되지 않는 한 약간의 stochasticity는 남는다. 다만 학습 과정에서 $\sigma \to 0$이 유리해지므로 결국 AutoEncoder의 동작에 수렴한다.
4.3 Rate-Distortion 해석
$\beta$의 조절은 정보이론적으로 깔끔한 의미를 가진다. ELBO의 두 항을 다음과 같이 다시 본다.
- Distortion $D = -\mathbb{E}_q[\log p_\theta(x|z)]$: 잠재 코드 $z$로부터 $x$를 복원할 때 발생하는 손실. compression으로 인한 정보 왜곡의 크기를 나타낸다.
- Rate $R = D_{\text{KL}}(q_\phi(z|x) \| p(z))$: 잠재 코드 $z$가 입력 $x$에 대해 담고 있는 정보의 양(단위: nats). 정보이론에서 채널의 전송률에 해당한다.
β-VAE의 loss는 $D + \beta R$로 표현되며, $\beta$를 조절하는 것은 Rate-Distortion curve 위에서 동작점을 이동시키는 작업과 같다. $\beta$가 큰 값일수록 rate $R$에 더 큰 페널티가 부과되므로, optimization은 잠재 코드가 담는 information을 줄이는 방향으로 (rate ↓), 그 대가로 reconstruction 정확도를 낮추는 방향으로 (distortion ↑) 동작점을 이동시킨다. 정보이론의 Rate-Distortion 이론에서 등장하는 distortion upper bound 아래의 rate 최소화 문제와 동일한 Lagrangian 구조이다.
- $\beta \downarrow$: rate가 커진다. 잠재 코드가 더 많은 정보를 담고, distortion이 줄어 reconstruction이 정밀해진다.
- $\beta \uparrow$: rate가 작아진다. 잠재 코드가 적은 정보만 담아 prior에 가까워지고, distortion이 커져 reconstruction이 흐려진다.
주목할 만한 극단은 $\beta \to \infty$의 경우이다. 이때 KL 항이 절대적으로 우세해져 encoder가 prior와 정확히 일치하는 분포 $q_\phi(z|x) = p(z)$를 출력하도록 강제된다. 그러나 이 경우 잠재 코드 $z$는 입력 $x$와 통계적으로 독립이 되어 어떠한 정보도 담지 못한다. 이를 posterior collapse라 부른다. decoder는 어떤 $x$가 들어와도 같은 분포에서 같은 mean을 내놓을 뿐이며, 사실상 모델이 무너진다.
4.4 Information information bottleneck 관점
β-VAE는 Information information bottleneck 원리 [17]의 한 구체화로도 해석된다. Information information bottleneck은 입력 $X$로부터 관련 출력 $Y$를 예측하는 표현 $Z$를 구성할 때, $I(Z; Y)$를 최대화하면서 $I(X; Z)$를 최소화하라는 원칙이다. 다음 Lagrangian을 푸는 것과 같다.
VAE의 self-supervised setting에서 $Y = X$로 두면, 이 원칙은 $X$의 reconstruction에 필요한 information만 $Z$에 담기도록 제약하는 것이 된다. β-VAE의 KL term은 $\mathbb{E}_{x \sim p_D}[D_{\text{KL}}(q_\phi(z|x) \| p(z))] = I(X; Z) + D_{\text{KL}}(q_\phi(z) \| p(z))$로 분해되어 $I(X; Z)$의 variational upper bound 역할을 하고, reconstruction term은 $I(Z; X)$의 (상수 차이를 가진) variational lower bound 역할을 한다. 두 항이 정확한 mutual information이 아니라 variational bound라는 점을 유의하면, β-VAE는 "입력의 의미 있는 information만 추출하라"는 information-theoretic principle의 한 구현으로 해석된다.
4.5 Disentanglement
$\beta > 1$인 영역에서 자주 관측되는 부수 현상이 disentanglement이다. 잠재 차원들이 서로 다른 의미적 요인(factor of variation)을 표현하는 양상이 나타난다. 얼굴 데이터셋에서 학습하면 한 차원은 rotation 각도, 다른 차원은 머리 색, 또 다른 차원은 표정과 같이 의미가 분리되는 식이다.
이 현상의 직관은 다음과 같다. KL term이 $q_\phi(z|x)$를 standard Gaussian(독립 Gaussian)에 가깝게 제약하므로 잠재 차원 간의 통계적 의존성이 약해진다. 모든 차원이 서로 독립이 되려면 각 차원이 서로 다른 의미를 담는 편이 가장 효율적이다.
VQ-VAE
latent space가 연속이라는 가정을 버리고 이산 코드로 대체한 변종이다. DALL-E 계열의 이미지 토크나이저처럼 현대 멀티모달 generative model의 기반 구조로 쓰인다.
5.1 동기: discretization가 필요한 이유
지금까지 다룬 모델에서 latent variable $z$는 모두 연속 vector였다. 그러나 머신러닝이 다루는 대상 중 많은 것이 본래 이산적인 정보로 더 잘 표현된다.
- 언어: 토큰, 단어, 문자는 본래 이산적이다.
- 의미 카테고리: "고양이"와 "강아지" 사이에는 중간 상태가 존재하지 않는다.
- 음성의 음소: 발화의 자연스러운 단위이다.
- 아이콘, 픽토그램, 픽셀 아트 또한 이산적이다.
실용적인 이유도 있다. 자연어 처리에서 Transformer 같은 모델은 이산 토큰 시퀀스를 입력으로 받는다. 만약 이미지의 잠재 표현을 이산 토큰 시퀀스로 만들 수 있다면, 텍스트와 이미지를 동일한 방식으로 처리하는 통합 모델이 가능해진다. 실제로 DALL-E는 VQ-VAE 계열의 이산 토크나이저로 이미지를 이산 토큰열로 바꾼 다음 Transformer로 자기회귀 생성을 수행한다 (DALL-E 1이 쓴 것은 정확히는 Gumbel-Softmax relaxation으로 학습한 discrete VAE이며, codebook 최근접 탐색을 쓰는 정통 VQ-VAE와 양자화 방식이 다르다).
5.2 핵심 아이디어: codebook quantization
VQ-VAE [19]의 핵심은 encoder의 출력을 미리 정의된 codebook의 한 항목으로 양자화한다는 점이다.
codebook은 $K$개의 학습 가능한 임베딩 벡터 $\{e_1, e_2, \ldots, e_K\} \subset \mathbb{R}^d$로 구성된 집합이다. $K$는 어휘 크기(예: 512, 1024, 8192), $d$는 임베딩 차원으로 encoder 출력 (latent) 차원과 같다.
VQ-VAE의 forward 과정은 (단일 잠재 vector $z_e \in \mathbb{R}^d$를 사용하는 경우) 다음과 같다.
- Encoder가 입력 $x$로부터 연속 vector $z_e(x) \in \mathbb{R}^d$를 출력한다.
- $z_e(x)$와 가장 가까운 codebook 항목을 찾는다: $k^\ast = \arg\min_k \|z_e(x) - e_k\|_2$.
- quantization된 잠재 vector를 $z_q(x) = e_{k^\ast}$로 정의한다.
- Decoder가 $\hat{x} = g_\theta(z_q)$를 출력한다.
최종적으로 decoder에 들어가는 $z_q$는 codebook의 한 항목이다. 잠재 표현이 사실상 정수 인덱스 $k^\ast \in \{1, \ldots, K\}$로 표현되는 셈이며, 이것이 discretization의 본질이다.
실제 이미지 VQ-VAE에서는 잠재 표현이 단일 vector가 아니라 spatial grid이다. Encoder는 입력 이미지를 $H \times W \times d$ 텐서로 출력하며 (예: $32 \times 32 \times 64$), 각 spatial 위치 $(i, j)$마다 $d$차원 vector $z_e^{(i,j)} \in \mathbb{R}^d$를 가진다. quantization는 각 위치별로 독립적으로 수행되어 그 위치의 codebook 인덱스 $k^\ast_{(i,j)}$를 얻는다. 결과적으로 한 이미지가 $H \times W$개의 codebook 인덱스로 이루어진 정수 token sequence로 표현된다.
이 정수 sequence가 곧 DALL-E 같은 모델에서 Transformer의 입력이 되는 image token이다. 텍스트가 단어 token sequence로 표현되듯이 이미지도 codebook 인덱스 sequence로 표현되어 동일한 autoregressive 처리가 가능해진다.
5.3 differentiation 문제와 Straight-Through Estimator
VQ-VAE도 학습 시 differentiation 문제에 부딪힌다. $\arg\min$ 연산이 differentiation 불가능하기 때문이다. 한 코드에서 다른 코드로 점프하는 순간 gradient가 정의되지 않는다. 그렇다고 VAE의 reparameterization 같은 깔끔한 해법을 그대로 쓸 수도 없다. 이산 변수에는 location-scale 변환이 적용되지 않기 때문이다.
VQ-VAE의 해결책은 실용적인 접근인 Straight-Through Estimator (STE)이다 [12].
Forward 때에는 quantization를 수행하여 $z_q = e_{k^*}$를 decoder에 전달한다.
Backward 때에는 quantization 연산이 없었던 것처럼 간주하여 gradient를 그대로 통과시킨다. 즉 $\partial \mathcal{L} / \partial z_e \approx \partial \mathcal{L} / \partial z_q$.
이론적으로 STE는 정확한 gradient가 아니지만, 실제 학습은 잘 진행된다. PyTorch 등에서의 구현은 다음과 같은 형태를 띤다.
여기서 $\text{sg}(\cdot)$는 stop-gradient 연산으로, forward에서는 값을 그대로 통과시키지만 backward에서는 gradient를 차단한다. 이 식은 forward에서 $z_q = e_{k^*}$로 동작하면서, $z_e$에 대한 gradient는 $z_q$에 대한 gradient와 같아지도록 한다.
5.4 Codebook 학습과 손실 구성
Codebook vector $\{e_k\}$ 자체도 학습 대상이다. 처음에는 무작위로 초기화되며, 데이터 분포를 잘 대표하도록 점진적으로 조정된다. VQ-VAE의 전체 loss는 세 항으로 구성된다.
표기를 명확히 한다. Reconstruction 항의 $z_q$는 forward 시 $e_{k^\ast}$와 같은 값이지만, 실제 구현에서는 5.3에서 본 STE 식 $z_q = z_e + \operatorname{sg}(e_{k^\ast} - z_e)$를 사용한다. 따라서 forward에서는 $z_q = e_{k^\ast}$로 동작하고, backward에서는 $z_e$에 대한 gradient가 $z_q$에 대한 gradient와 같아진다. Codebook loss와 commitment loss는 같은 거리 $\|z_e - e_{k^\ast}\|^2$를 stop-gradient만 다르게 걸어 두 번 사용한 항이다.
- Reconstruction loss: Decoder가 $z_q$로부터 $x$를 잘 복원하도록 만든다. STE에 의해 gradient가 encoder까지 전파된다.
- Codebook loss: $\|\operatorname{sg}(z_e) - e\|^2$. $z_e$ 쪽에 stop-gradient를 걸어 codebook vector $e$만 갱신된다. Codebook 항목이 encoder output에 가까워지도록 이동하며, k-means의 centroid update와 유사한 역할이다.
- Commitment loss: $\|z_e - \operatorname{sg}(e)\|^2$. $e$ 쪽에 stop-gradient를 걸어 encoder만 갱신된다. Encoder output이 선택된 codebook 항목에서 지나치게 멀어지지 않도록 제약하며, 일반적으로 $\beta = 0.25$로 둔다.
같은 거리 항을 두 번 쓰되 한쪽에만 stop-gradient를 거는 구조이다. Codebook loss는 codebook만, commitment loss는 encoder만 움직이게 하여 두 쪽이 서로를 향해 다가가게 만든다. $\beta$는 두 update 속도의 비율을 조절한다.
실제로는 codebook을 gradient로 갱신하는 대신 exponential moving average (EMA)로 더 안정적으로 갱신하는 방식이 자주 쓰인다. 이 EMA 갱신은 원조 VQ-VAE 논문 [19]의 부록에 이미 제시된 기법이다.
5.5 후속 모델들
VQ-VAE는 그 자체로도 강력한 모델이지만, 더 중요한 영향은 후속 모델들에 끼친 것이다.
- VQ-VAE-2 [20]: 계층적 codebook으로 고해상도 이미지를 생성한다.
- DALL-E [22]: 텍스트와, VQ-VAE 계열 토크나이저로 만든 이미지 토큰을 같은 자기회귀 Transformer로 처리한다.
- VQ-GAN [21]: codebook 학습에 adversarial 손실을 결합하여 더 정밀한 이미지 표현을 얻는다.
- Stable Diffusion (Latent Diffusion) [9]: VAE가 형성한 latent space 위에서 diffusion을 수행한다. 픽셀 공간에서 직접 diffusion을 하는 것보다 훨씬 효율적이다. 배포된 Stable Diffusion v1.x의 autoencoder는 VQ가 아니라 KL 정규화된 연속 VAE이다 (3장에서 다룬 KL-VAE의 직계). LDM 원논문은 VQ 정규화와 KL 정규화 두 변종을 모두 실험했고, 출시된 가중치는 KL 변종을 채택했다. VQ-GAN에서 가져온 것은 autoencoder 아키텍처와 perceptual + adversarial 손실이지 codebook 양자화가 아니다.
여기서 끌어낼 수 있는 통찰은, 이미지를 픽셀 단위로 다루는 것보다 latent space(이산이든 연속이든) 위에서 다루는 편이 훨씬 효율적이며, VQ-VAE의 quantization 아이디어가 그 통로를 연 출발점이라는 점이다.
강의의 마무리
본 강의의 흐름이 현대 generative model로 어떻게 이어지는지를 짚고, 학생이 강의를 복습할 때 의지할 수 있는 리딩 가이드를 정리한다.
6.1 다루지 않은 모델들
VAE 계열의 "흐릿함"이라는 약점에 대해 다른 방식으로 대응하는 generative model들이 있다.
- Normalizing Flows: 가역 변환으로 정확한 likelihood를 계산한다. 흐림이 없는 대신 구조적 제약이 강하다.
- GAN: 적대적 학습으로 선명한 이미지를 만들어낸다. 학습 불안정성과 mode collapse 문제가 따라온다.
- Diffusion Models: noise를 점진적으로 제거한다. 현재 이미지 생성의 SOTA이며, 안정적인 학습과 높은 품질의 균형을 이룬다.
주목할 점은, 가장 강력한 최신 모델인 Stable Diffusion조차 latent space 위에서 동작한다는 사실이다. 그리고 그 latent space는 3장에서 배운 바로 그 KL 정규화 VAE로 만들어진다. 곧 이 강의에서 유도한 KL-VAE가 그대로 현대 멀티모달 generative model의 핵심 부품으로 들어간다. 본 강의의 내용은 과거의 이야기가 아니라 현재 가장 활발한 generative model 연구의 기반이다.
6.2 참고문헌
본 강의에서 인용한 자료들의 전체 목록 (IEEE 인용 형식).
- H. Bourlard and Y. Kamp, "Auto-association by multilayer perceptrons and singular value decomposition," Biological Cybernetics, vol. 59, no. 4–5, pp. 291–294, 1988.
- P. Baldi and K. Hornik, "Neural networks and principal component analysis: Learning from examples without local minima," Neural Networks, vol. 2, no. 1, pp. 53–58, 1989.
- K. Kawaguchi, "Deep learning without poor local minima," in Proc. NeurIPS, 2016.
- K. Pearson, "On lines and planes of closest fit to systems of points in space," Philosophical Magazine, vol. 2, pp. 559–572, 1901.
- H. Hotelling, "Analysis of a complex of statistical variables into principal components," J. Educational Psychology, vol. 24, pp. 417–441, 1933.
- D. E. Rumelhart, G. E. Hinton, and R. J. Williams, "Learning representations by back-propagating errors," Nature, vol. 323, pp. 533–536, 1986.
- M. A. Kramer, "Nonlinear principal component analysis using autoassociative neural networks," AIChE Journal, vol. 37, no. 2, pp. 233–243, 1991.
- G. E. Hinton and R. R. Salakhutdinov, "Reducing the dimensionality of data with neural networks," Science, vol. 313, no. 5786, pp. 504–507, 2006.
- R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, "High-resolution image synthesis with latent diffusion models," in Proc. CVPR, 2022.
- P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, "Extracting and composing robust features with denoising autoencoders," in Proc. ICML, 2008.
- S. Rifai, P. Vincent, X. Muller, X. Glorot, and Y. Bengio, "Contractive auto-encoders: Explicit invariance during feature extraction," in Proc. ICML, 2011.
- Y. Bengio, L. Yao, G. Alain, and P. Vincent, "Generalized denoising auto-encoders as generative models," in Proc. NeurIPS, 2013.
- D. P. Kingma and M. Welling, "Auto-encoding variational Bayes," in Proc. ICLR, 2014.
- I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. Cambridge, MA, USA: MIT Press, 2016.
- K. P. Murphy, Probabilistic Machine Learning: Advanced Topics. Cambridge, MA, USA: MIT Press, 2023.
- I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, "β-VAE: Learning basic visual concepts with a constrained variational framework," in Proc. ICLR, 2017.
- N. Tishby, F. C. Pereira, and W. Bialek, "The information information bottleneck method," in Proc. 37th Annu. Allerton Conf. Commun., Control, Comput., 1999.
- F. Locatello, S. Bauer, M. Lucic, G. Rätsch, S. Gelly, B. Schölkopf, and O. Bachem, "Challenging common assumptions in the unsupervised learning of disentangled representations," in Proc. ICML, 2019.
- A. van den Oord, O. Vinyals, and K. Kavukcuoglu, "Neural discrete representation learning," in Proc. NeurIPS, 2017.
- A. Razavi, A. van den Oord, and O. Vinyals, "Generating diverse high-fidelity images with VQ-VAE-2," in Proc. NeurIPS, 2019.
- P. Esser, R. Rombach, and B. Ommer, "Taming transformers for high-resolution image synthesis," in Proc. CVPR, 2021.
- A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, "Zero-shot text-to-image generation," in Proc. ICML, 2021.
- C. Doersch, "Tutorial on variational autoencoders," arXiv:1606.05908, 2016.
- S. H. Friedberg, A. J. Insel, and L. E. Spence, Linear Algebra, 4th ed. Upper Saddle River, NJ, USA: Pearson, 2003.
- M. E. Tipping and C. M. Bishop, "Probabilistic principal component analysis," J. Royal Statistical Society B, vol. 61, no. 3, pp. 611–622, 1999.
- G. E. Hinton and R. S. Zemel, "Autoencoders, minimum description length and Helmholtz free energy," in Proc. NeurIPS, 1994.
심화 학습 경로: VAE를 처음 익히는 독자는 [23]을 권하며, 체계적인 교과서로는 [15]의 Chapter 21이 표준이다. 본 강의의 수학적 기반에 더 깊이 들어가려면 [14]의 Chapter 5, 14, 그리고 [13]의 원논문을 직접 읽기를 권한다.
실습으로는 PyTorch나 TensorFlow를 써서 MNIST 위에서 VAE를 직접 구현해 보는 것을 권한다. 100줄 정도의 코드로 작성할 수 있으며, latent space를 시각화하고 보간이나 무작위 생성을 직접 확인해 보는 편이 책으로 읽는 것보다 훨씬 큰 도움이 된다.
6.3 리딩 가이드
강의를 복습하거나 자료를 다시 펼쳐 볼 때 참고할 수 있도록, 각 장의 핵심을 한 표로 정리한다.
| 장 | 중심 개념 | 핵심 정의·명제·식 | 핵심 시각화 |
|---|---|---|---|
| 0장 | 강의 전체 조망 | VAE 계열의 역사적 계보 | 01 (역사 계보 타임라인) |
| 1장 | encoder-decoder abstraction | 정의 1.1, 세 가지 부호화 분류 (length-preserving · redundant · compressive) | 02 (암호학 파이프라인), 03 (세 가지 latent space 미리 보기) |
| 2장 | AutoEncoder의 구조·표현 학습·한계 (generative model로서의 실패) | 정의 2.1 (AutoEncoder), 정의 2.2 (generative model), Gaussian/Bernoulli decoder의 NLL 유도 (2.2), Frobenius norm² 손실, centered 데이터와 covariance (2.3.1), linear AE = PCA + invertible $C$ 모호성 (2.3), Probabilistic PCA (2.4), 비선형 deep AE (2.5), 점이 아닌 분포 매핑 (2.6) | 04 (구조 지도), 05 (hourglass 구조), 06 (점 매핑 vs 분포 매핑) |
| 3장 | VAE의 정의, ELBO, reparameterization | 두 joint distribution (3.1.2 / 3.3.1), ELBO 유도 (3.3), 명제 3.1 Gaussian affine 변환, 알고리즘 3.1 학습 사이클 | 07 (decoder 두 해석), 08 (전체 구조), 09 (reparam 비교) |
| 4장 | β로 표현의 성격 조절 | β-VAE 손실, Rate-Distortion 해석 ($D + \beta R$), posterior collapse | 10 (β 슬라이더) |
| 5장 | latent space discretization | codebook quantization, Straight-Through Estimator, 3항 손실 (reconstruction + codebook + commitment) | 11 (codebook 격자) |
강의 전체를 관통하는 핵심 개념 네 가지는 다음과 같다.
- 두 분포 모델의 짝 구조. generative model $p_\theta(z, x) = p(z)\,p_\theta(x \mid z)$와 recognition model $q_\phi(z \mid x)$. decoder $g_\theta$와 encoder $f_\phi$가 각각을 neural network으로 구현한다.
- ELBO의 두 항. reconstruction 항 $\mathbb{E}_{q_\phi}[\log p_\theta(x \mid z)]$과 KL 항 $D_{\text{KL}}(q_\phi(z \mid x) \,\|\, p(z))$. 이 둘이 균형을 이루는 지점이 VAE의 학습 해이다.
- Reparameterization trick. 명제 3.1의 Gaussian affine 변환에 따라, 샘플링 $z \sim q_\phi(z \mid x)$를 외부 noise $\epsilon$과 결정론적 변환 $z = \mu + \sigma \odot \epsilon$으로 분해한다. 이로써 gradient가 encoder까지 흐른다.
- latent space를 다루는 세 방식. 점(AE) / 분포(VAE, β-VAE) / 이산 코드(VQ-VAE). 1장 끝의 시각화 03이 이 세 방식을 한 장으로 비교한다.
실제로 자료를 읽어 나가는 권장 순서는 다음과 같다. 1장에서 abstraction을 보고, 2장에서 AutoEncoder의 정의·수학적 토대·한계를 한 번에 따라간다. 3장 도입부 (3.1~3.2)에서 두 분포 모델의 짝 구조와 variational approximation를 익히고, 3.3 ELBO 유도와 3.4 Gaussian KL을 따라가며 학습 목표의 닫힌 형태를 본다. 3.5.1~3.5.3은 학습이 differentiation 가능해지는 기제이며, 3.5.4 알고리즘 3.1이 모든 요소를 한 페이지에 모은다. 4장과 5장은 3장의 변주이며 골격이 잡힌 뒤 가볍게 읽힌다.
6.4 부록: Notation 정리
본 강의에서 사용한 기호를 한자리에 모은다. 각 기호의 차원과 정의, 그리고 구체적 예시를 함께 적는다. 자료를 읽다가 기호의 의미가 불확실할 때 이 표로 돌아오면 된다.
차원과 데이터
| 기호 | 차원 | 의미와 예시 |
|---|---|---|
| $x$ | $\mathbb{R}^D$ | 한 개의 데이터 포인트 (입력). 예: MNIST 이미지 한 장을 펼친 vector. |
| $x_i$ | $\mathbb{R}^D$ | 데이터셋의 $i$번째 sample. $i = 1, \ldots, N$. |
| $D$ | 스칼라 | 한 데이터 포인트의 차원 (입력 차원). 예: MNIST는 $D = 784$ ($28 \times 28$). |
| $d$ | 스칼라 | latent 차원 (잠재 공간의 차원). $d < D$. 예: $d = 32$. VQ-VAE의 codebook 임베딩 차원도 이 $d$이다 (encoder 출력 공간과 같은 공간). |
| $N$ | 스칼라 | 데이터셋 안의 sample 개수. |
| $\mathcal{D}$ | 집합 | 데이터셋 전체. $\mathcal{D} = \{x_1, \ldots, x_N\}$. |
| $z$ | $\mathbb{R}^d$ | latent vector (잠재 표현). encoder가 만든 $x$의 압축 표현. |
| $\hat{x}$ | $\mathbb{R}^D$ | 재구성된 데이터. decoder의 출력. 학습 목표는 $\hat{x} \approx x$. |
함수와 파라미터
| 기호 | 유형 | 의미와 예시 |
|---|---|---|
| $f_\phi$ | $\mathbb{R}^D \to \mathbb{R}^d$ | encoder. 입력을 latent로 보내는 함수. VAE에서는 분포 $q_\phi(z \mid x)$의 파라미터를 출력한다. |
| $g_\theta$ | $\mathbb{R}^d \to \mathbb{R}^D$ | decoder. latent를 데이터 공간으로 보내는 함수. |
| $\phi$ | 파라미터 | encoder의 학습 파라미터 (neural network 가중치). |
| $\theta$ | 파라미터 | decoder의 학습 파라미터. |
| $W_e$ | $\mathbb{R}^{d \times D}$ | Linear AE의 선형 encoder 행렬 (2.3). |
| $W_d$ | $\mathbb{R}^{D \times d}$ | Linear AE의 선형 decoder 행렬 (2.3). |
| $P$ | $\mathbb{R}^{D \times D}$ | Linear AE의 합성 $P = W_d W_e$. rank $\leq d$. critical point에서 orthogonal projection. |
확률 분포
| 기호 | 정의역 | 의미와 예시 |
|---|---|---|
| $p(z)$ | $z$ 위의 분포 | latent prior. VAE에서 $p(z) = \mathcal{N}(0, I_d)$. |
| $p_\theta(x \mid z)$ | $x$ 위의 조건부 분포 | decoder가 정의하는 분포. 연속 데이터면 Gaussian, 이진 데이터면 Bernoulli. |
| $q_\phi(z \mid x)$ | $z$ 위의 조건부 분포 | encoder가 정의하는 근사 posterior (recognition model). VAE에서 $\mathcal{N}(\mu_\phi(x), \operatorname{diag}(\sigma_\phi^2(x)))$. |
| $p_\theta(x)$ | $x$ 위의 분포 | 모델이 정의하는 데이터의 marginal likelihood. $p_\theta(x) = \int p_\theta(x \mid z) p(z)\, dz$. |
| $p_{\mathcal{D}}(x)$ | $x$ 위의 분포 | 데이터 생성 분포 (empirical distribution). 데이터셋에서 균등하게 뽑는 분포. |
| $\mu, \sigma$ | $\mathbb{R}^d$ | $q_\phi(z \mid x)$ Gaussian의 mean과 표준편차. encoder $f_\phi$가 출력한다. |
| $\Sigma_x$ | $\mathbb{R}^{D \times D}$ | centered 데이터의 covariance matrix. $\Sigma_x = \frac{1}{N}\sum_i x_i x_i^\top$ (2.3.1). |
학습 목표
| 기호 | 의미와 예시 |
|---|---|
| $\mathcal{L}$ | 손실 함수. AE에서는 reconstruction 손실, VAE에서는 ELBO의 음수. |
| ELBO | Evidence Lower Bound. $\log p_\theta(x)$의 하한. reconstruction 항과 KL 항의 합 (3.3). |
| $D_{\text{KL}}(\cdot \,\|\, \cdot)$ | Kullback-Leibler divergence. 두 분포 사이의 비대칭 거리 측도. |
| $\epsilon$ | reparameterization의 외부 noise. $\epsilon \sim \mathcal{N}(0, I_d)$, $z = \mu + \sigma \odot \epsilon$ (3.5). |
| $\beta$ | β-VAE에서 KL 항에 붙는 가중치 (4장). $\beta = 1$이면 표준 VAE. |
VQ-VAE 전용 기호
| 기호 | 차원 | 의미와 예시 |
|---|---|---|
| $e_k$ | $\mathbb{R}^d$ | codebook의 $k$번째 임베딩 벡터. $k = 1, \ldots, K$. |
| $K$ | 스칼라 | codebook 크기 (어휘 크기). 예: $K = 512, 1024, 8192$. |
| $z_e$ | $\mathbb{R}^d$ | encoder의 연속 출력 (quantization 전). |
| $z_q$ | $\mathbb{R}^d$ | quantization된 latent. $z_q = e_{k^\ast}$, $k^\ast = \arg\min_k \|z_e - e_k\|$. |
| $\operatorname{sg}[\cdot]$ | 연산자 | stop-gradient. forward에서는 항등, backward에서는 gradient를 0으로 만든다 (5.3). |